開始使用¶
這個非常簡單的案例研究旨在讓您快速上手 statsmodels。從原始資料開始,我們將展示估計統計模型和繪製診斷圖所需的步驟。我們只會使用 statsmodels 或其 pandas 和 patsy 相依性提供的函數。
載入模組與函數¶
在安裝 statsmodels 及其相依性後,我們載入一些模組與函數
In [1]: import statsmodels.api as sm
In [2]: import pandas
In [3]: from patsy import dmatrices
pandas 建構於 numpy 陣列之上,以提供豐富的資料結構與資料分析工具。pandas.DataFrame 函數提供標記的 (可能異質的) 資料陣列,類似於 R 的 “data.frame”。pandas.read_csv 函數可用於將逗號分隔值檔案轉換為 DataFrame 物件。
patsy 是一個 Python 函式庫,用於描述統計模型並使用類似 R 的公式建立設計矩陣。
注意
這個範例使用 API 介面。請參閱匯入路徑與結構,以了解匯入 API 介面 (statsmodels.api 和 statsmodels.tsa.api) 與直接從定義模型的模組匯入之間的差異。
資料¶
我們下載Guerry 資料集,這是支援安德烈-米歇爾·蓋瑞 (Andre-Michel Guerry) 1833 年《法國道德統計論文》的歷史資料集。該資料集以逗號分隔值格式 (CSV) 託管在Rdatasets 儲存庫中。我們可以將檔案下載到本機,然後使用 read_csv 載入,但 pandas 會自動為我們處理這一切
In [4]: df = sm.datasets.get_rdataset("Guerry", "HistData").data
輸入/輸出文件頁面顯示如何從各種其他格式匯入。
我們選取感興趣的變數,並查看最後 5 列
In [5]: vars = ['Department', 'Lottery', 'Literacy', 'Wealth', 'Region']
In [6]: df = df[vars]
In [7]: df[-5:]
Out[7]:
Department Lottery Literacy Wealth Region
81 Vienne 40 25 68 W
82 Haute-Vienne 55 13 67 C
83 Vosges 14 62 82 E
84 Yonne 51 47 30 C
85 Corse 83 49 37 NaN
請注意,Region 欄中缺少一個觀測值。我們使用 pandas 提供的 DataFrame 方法將其消除
In [8]: df = df.dropna()
In [9]: df[-5:]
Out[9]:
Department Lottery Literacy Wealth Region
80 Vendee 68 28 56 W
81 Vienne 40 25 68 W
82 Haute-Vienne 55 13 67 C
83 Vosges 14 62 82 E
84 Yonne 51 47 30 C
實質動機與模型¶
我們想知道 1820 年代法國 86 個部門的識字率是否與人均皇家彩券賭注相關。我們需要控制每個部門的財富水準,而且我們也想在迴歸方程式的右側包含一系列虛擬變數,以控制因地區效應而產生的未觀察到的異質性。該模型使用普通最小平方迴歸 (OLS) 進行估計。
設計矩陣 (endog & exog)¶
若要擬合 statsmodels 涵蓋的大多數模型,您需要建立兩個設計矩陣。第一個是內生變數的矩陣 (即,依變數、反應變數、被解釋變數等)。第二個是外生變數的矩陣 (即,獨立變數、預測變數、迴歸變數等)。OLS 係數估計值通常按以下方式計算
其中 \(y\) 是每人彩券賭注 (Lottery) 的 \(N \times 1\) 資料欄。\(X\) 是 \(N \times 7\),其中包含截距、Literacy 和 Wealth 變數,以及 4 個區域二元變數。
patsy 模組提供一個便利的函數,可使用類似 R 的公式來準備設計矩陣。您可以在此處找到更多資訊。
我們使用 patsy 的 dmatrices 函數來建立設計矩陣
In [10]: y, X = dmatrices('Lottery ~ Literacy + Wealth + Region', data=df, return_type='dataframe')
產生的矩陣/資料框架如下所示
In [11]: y[:3]
Out[11]:
Lottery
0 41.0
1 38.0
2 66.0
In [12]: X[:3]
Out[12]:
Intercept Region[T.E] Region[T.N] ... Region[T.W] Literacy Wealth
0 1.0 1.0 0.0 ... 0.0 37.0 73.0
1 1.0 0.0 1.0 ... 0.0 51.0 22.0
2 1.0 0.0 0.0 ... 0.0 13.0 61.0
[3 rows x 7 columns]
請注意,dmatrices 已
將分類 Region 變數分割成一組指標變數。
將常數新增至外生迴歸變數矩陣。
傳回
pandas資料框架,而非簡單的 numpy 陣列。這很有用,因為資料框架允許statsmodels在報告結果時延續元資料 (例如,變數名稱)。
當然,可以變更上述行為。請參閱patsy 文件頁面。
模型擬合與摘要¶
在 statsmodels 中擬合模型通常涉及 3 個簡單步驟
使用模型類別來描述模型
使用類別方法擬合模型
使用摘要方法檢查結果
對於 OLS,這可以透過以下方式實現
In [13]: mod = sm.OLS(y, X) # Describe model
In [14]: res = mod.fit() # Fit model
In [15]: print(res.summary()) # Summarize model
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.338
Model: OLS Adj. R-squared: 0.287
Method: Least Squares F-statistic: 6.636
Date: Thu, 03 Oct 2024 Prob (F-statistic): 1.07e-05
Time: 16:15:27 Log-Likelihood: -375.30
No. Observations: 85 AIC: 764.6
Df Residuals: 78 BIC: 781.7
Df Model: 6
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 38.6517 9.456 4.087 0.000 19.826 57.478
Region[T.E] -15.4278 9.727 -1.586 0.117 -34.793 3.938
Region[T.N] -10.0170 9.260 -1.082 0.283 -28.453 8.419
Region[T.S] -4.5483 7.279 -0.625 0.534 -19.039 9.943
Region[T.W] -10.0913 7.196 -1.402 0.165 -24.418 4.235
Literacy -0.1858 0.210 -0.886 0.378 -0.603 0.232
Wealth 0.4515 0.103 4.390 0.000 0.247 0.656
==============================================================================
Omnibus: 3.049 Durbin-Watson: 1.785
Prob(Omnibus): 0.218 Jarque-Bera (JB): 2.694
Skew: -0.340 Prob(JB): 0.260
Kurtosis: 2.454 Cond. No. 371.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
res 物件有許多實用的屬性。例如,我們可以輸入以下內容來擷取參數估計值和 R 平方
In [16]: res.params
Out[16]:
Intercept 38.651655
Region[T.E] -15.427785
Region[T.N] -10.016961
Region[T.S] -4.548257
Region[T.W] -10.091276
Literacy -0.185819
Wealth 0.451475
dtype: float64
In [17]: res.rsquared
Out[17]: np.float64(0.337950869192882)
輸入 dir(res) 以取得完整的屬性清單。
如需更多資訊和範例,請參閱迴歸文件頁面
診斷與規格檢定¶
statsmodels 可讓您執行一系列實用的迴歸診斷與規格檢定。例如,套用用於線性度的彩虹檢定 (虛無假設是關係正確地建模為線性)
In [18]: sm.stats.linear_rainbow(res)
Out[18]: (np.float64(0.847233997615691), np.float64(0.6997965543621644))
誠然,上面產生的輸出不是很詳細,但我們從閱讀文件字串 (還有 print(sm.stats.linear_rainbow.__doc__)) 得知,第一個數字是 F 統計量,第二個數字是 p 值。
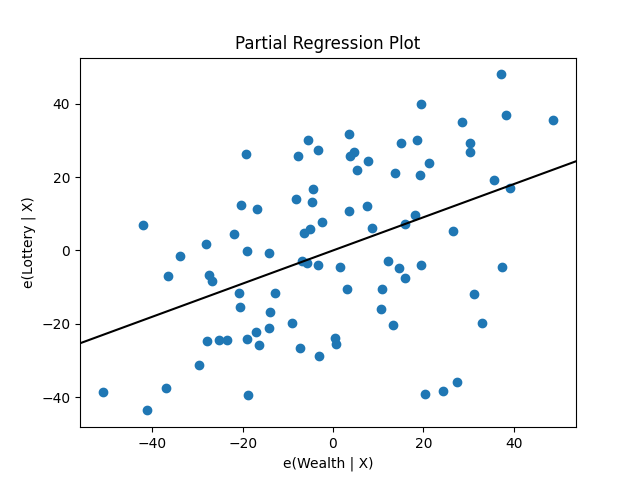
statsmodels 也提供圖形函數。例如,我們可以透過以下方式繪製一組迴歸變數的部分迴歸圖
In [19]: sm.graphics.plot_partregress('Lottery', 'Wealth', ['Region', 'Literacy'],
....: data=df, obs_labels=False)
....:
Out[19]: <Figure size 640x480 with 1 Axes>
文件¶
可以使用 IPython 工作階段中的 webdoc 來存取文件。
開啟瀏覽器並顯示線上文件 |
更多¶
恭喜!您已準備好繼續學習目錄中的其他主題