向量自迴歸 tsa.vector_ar¶
statsmodels.tsa.vector_ar 包含使用 向量自迴歸 (VAR) 和 向量誤差校正模型 (VECM) 同時建模和分析多個時間序列的方法。
VAR(p) 過程¶
我們有興趣建模一個 \(T \times K\) 的多變量時間序列 \(Y\),其中 \(T\) 表示觀測值的數量,而 \(K\) 表示變數的數量。估計時間序列及其滯後值之間關係的一種方法是向量自迴歸過程
其中 \(A_i\) 是一個 \(K \times K\) 的係數矩陣。
我們在很大程度上遵循 Lutkepohl (2005) 的方法和符號,這裡我們不再詳述。
模型擬合¶
注意
以下引用的類別可透過 statsmodels.tsa.api 模組存取。
若要估計 VAR 模型,必須先使用同質或結構化 dtype 的 ndarray 建立模型。當使用結構化或記錄陣列時,該類別將使用傳遞的變數名稱。否則,它們可以明確地傳遞
# some example data
In [1]: import numpy as np
In [2]: import pandas
In [3]: import statsmodels.api as sm
In [4]: from statsmodels.tsa.api import VAR
In [5]: mdata = sm.datasets.macrodata.load_pandas().data
# prepare the dates index
In [6]: dates = mdata[['year', 'quarter']].astype(int).astype(str)
In [7]: quarterly = dates["year"] + "Q" + dates["quarter"]
In [8]: from statsmodels.tsa.base.datetools import dates_from_str
In [9]: quarterly = dates_from_str(quarterly)
In [10]: mdata = mdata[['realgdp','realcons','realinv']]
In [11]: mdata.index = pandas.DatetimeIndex(quarterly)
In [12]: data = np.log(mdata).diff().dropna()
# make a VAR model
In [13]: model = VAR(data)
注意
VAR 類別假設傳遞的時間序列是平穩的。非平穩或具有趨勢的數據通常可以透過一階差分或其他方法轉換為平穩的。對於直接分析非平穩時間序列,標準的穩定 VAR(p) 模型是不適用的。
要實際執行估計,請使用所需的落後期數呼叫 fit 方法。或者,您可以讓模型根據標準資訊準則選擇落後期數 (請參閱下文)
In [14]: results = model.fit(2)
In [15]: results.summary()
Out[15]:
Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Thu, 03, Oct, 2024
Time: 16:15:42
--------------------------------------------------------------------
No. of Equations: 3.00000 BIC: -27.5830
Nobs: 200.000 HQIC: -27.7892
Log likelihood: 1962.57 FPE: 7.42129e-13
AIC: -27.9293 Det(Omega_mle): 6.69358e-13
--------------------------------------------------------------------
Results for equation realgdp
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const 0.001527 0.001119 1.365 0.172
L1.realgdp -0.279435 0.169663 -1.647 0.100
L1.realcons 0.675016 0.131285 5.142 0.000
L1.realinv 0.033219 0.026194 1.268 0.205
L2.realgdp 0.008221 0.173522 0.047 0.962
L2.realcons 0.290458 0.145904 1.991 0.047
L2.realinv -0.007321 0.025786 -0.284 0.776
==============================================================================
Results for equation realcons
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const 0.005460 0.000969 5.634 0.000
L1.realgdp -0.100468 0.146924 -0.684 0.494
L1.realcons 0.268640 0.113690 2.363 0.018
L1.realinv 0.025739 0.022683 1.135 0.257
L2.realgdp -0.123174 0.150267 -0.820 0.412
L2.realcons 0.232499 0.126350 1.840 0.066
L2.realinv 0.023504 0.022330 1.053 0.293
==============================================================================
Results for equation realinv
==============================================================================
coefficient std. error t-stat prob
------------------------------------------------------------------------------
const -0.023903 0.005863 -4.077 0.000
L1.realgdp -1.970974 0.888892 -2.217 0.027
L1.realcons 4.414162 0.687825 6.418 0.000
L1.realinv 0.225479 0.137234 1.643 0.100
L2.realgdp 0.380786 0.909114 0.419 0.675
L2.realcons 0.800281 0.764416 1.047 0.295
L2.realinv -0.124079 0.135098 -0.918 0.358
==============================================================================
Correlation matrix of residuals
realgdp realcons realinv
realgdp 1.000000 0.603316 0.750722
realcons 0.603316 1.000000 0.131951
realinv 0.750722 0.131951 1.000000
可以使用 matplotlib 將數據視覺化幾種方式。
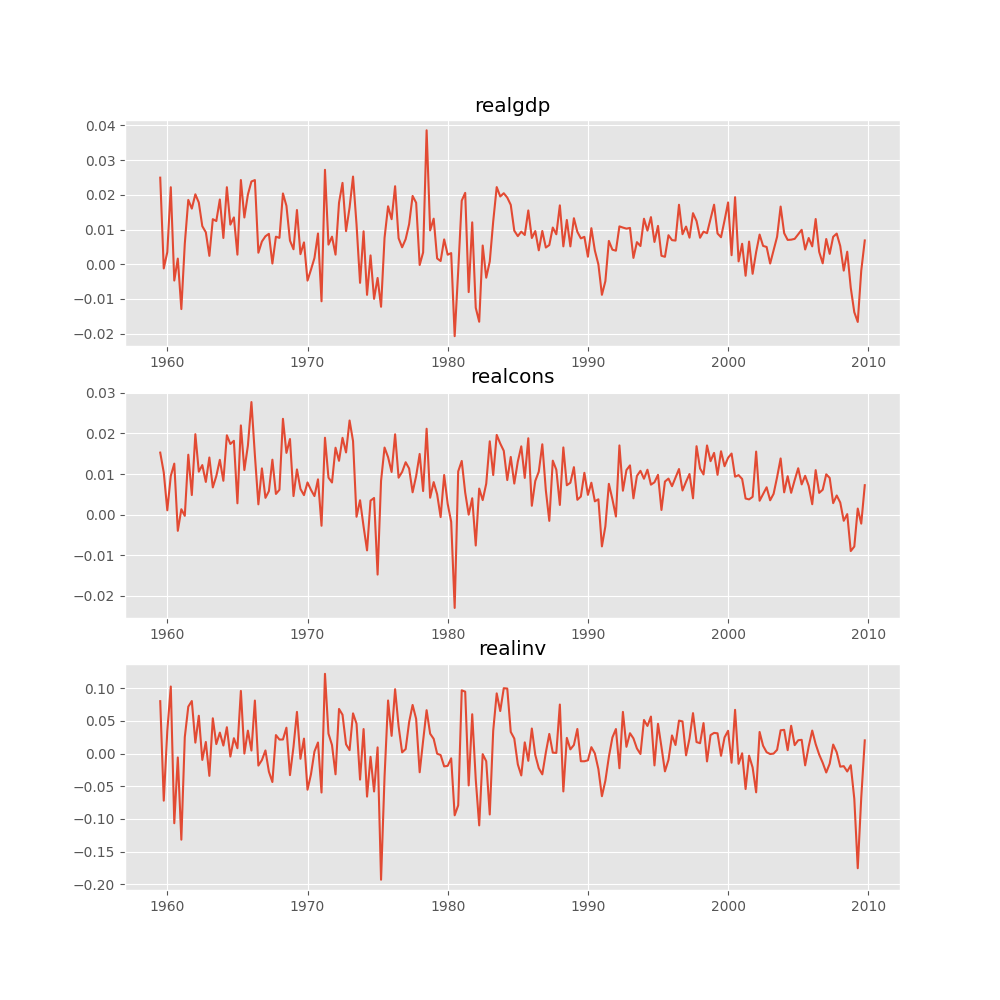
繪製輸入時間序列
In [16]: results.plot()
Out[16]: <Figure size 1000x1000 with 3 Axes>
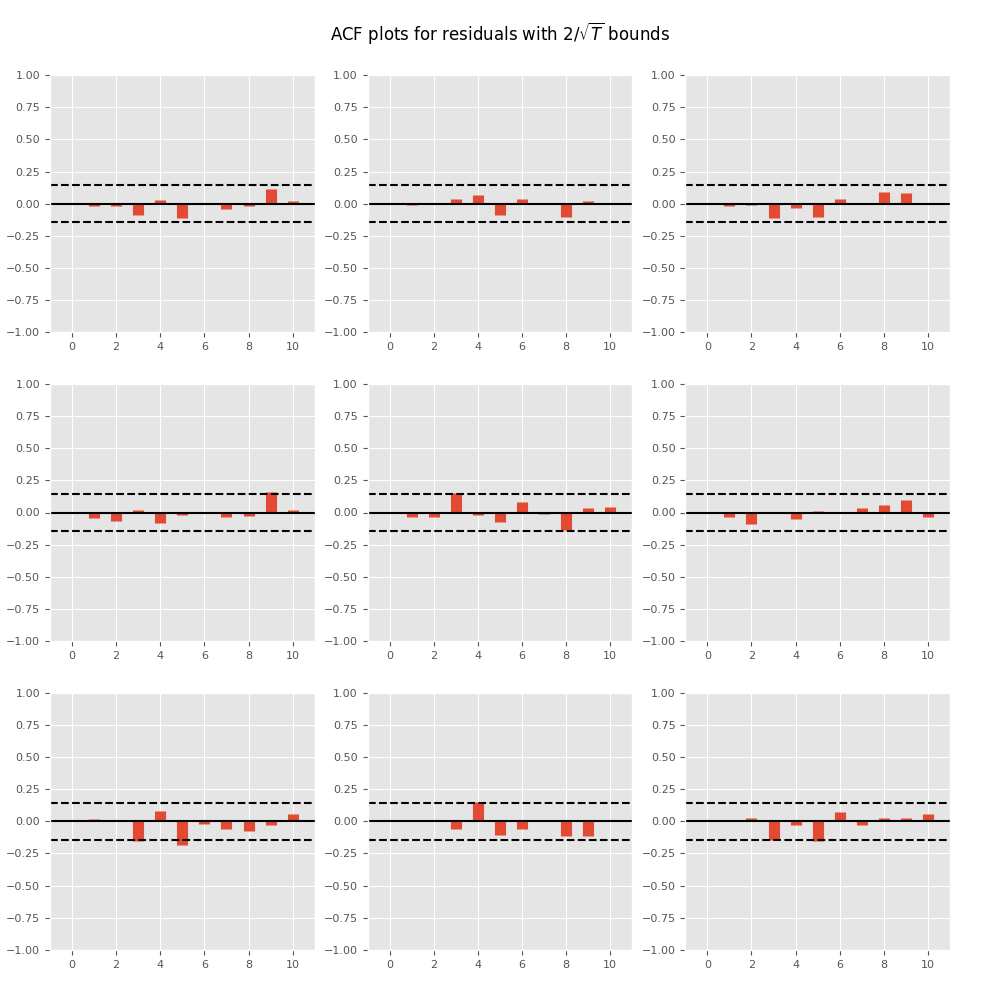
繪製時間序列自相關函數
In [17]: results.plot_acorr()
Out[17]: <Figure size 1000x1000 with 9 Axes>
落後期數選擇¶
選擇落後期數可能是一個難題。標準分析採用似然檢定或基於資訊準則的階數選擇。我們已實作後者,可透過 VAR 類別存取
In [18]: model.select_order(15)
Out[18]: <statsmodels.tsa.vector_ar.var_model.LagOrderResults at 0x7f18fd4e8430>
當呼叫 fit 函數時,可以傳遞最大落後期數和用於階數選擇的順序準則
In [19]: results = model.fit(maxlags=15, ic='aic')
預測¶
線性預測器是均方誤差方面最佳的 h 步前預測
我們可以使用 forecast 函數來產生此預測。請注意,我們必須指定預測的「初始值」
In [20]: lag_order = results.k_ar
In [21]: results.forecast(data.values[-lag_order:], 5)
Out[21]:
array([[ 0.0062, 0.005 , 0.0092],
[ 0.0043, 0.0034, -0.0024],
[ 0.0042, 0.0071, -0.0119],
[ 0.0056, 0.0064, 0.0015],
[ 0.0063, 0.0067, 0.0038]])
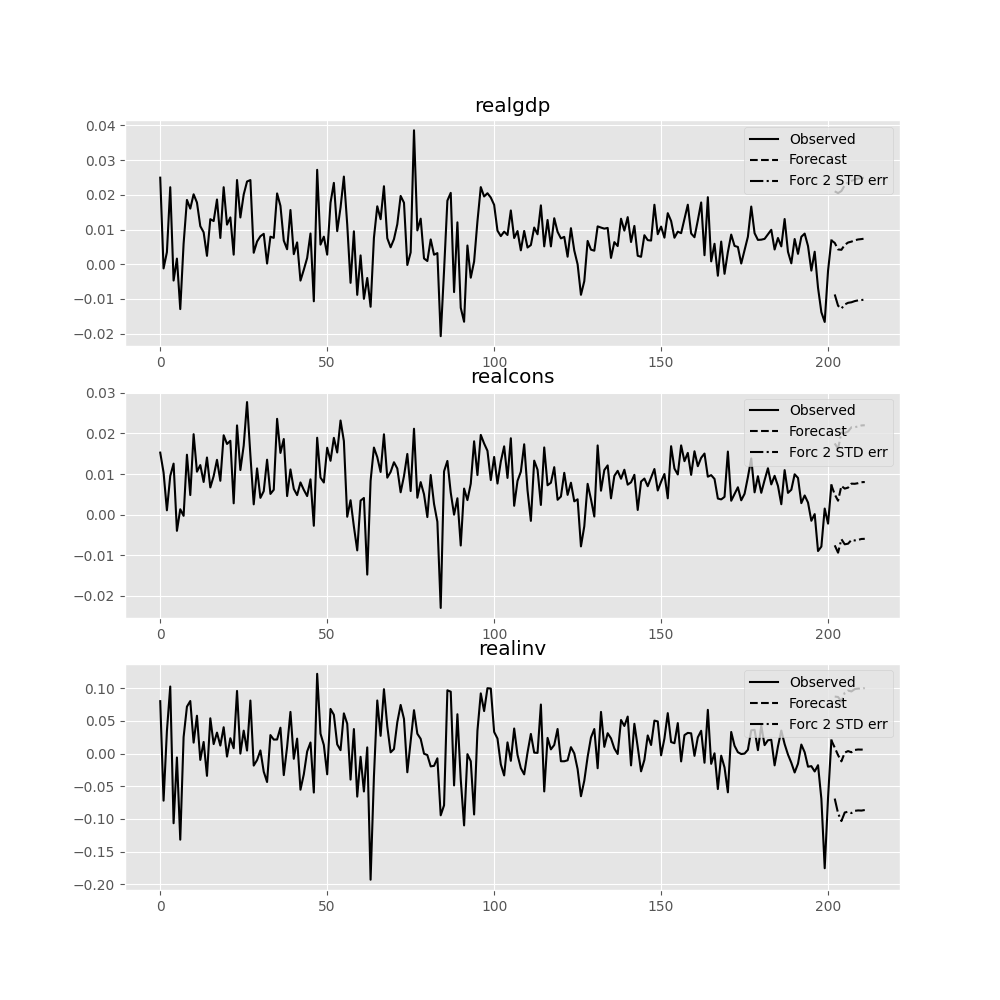
forecast_interval 函數將產生上述預測以及漸近標準誤差。這些可以使用 plot_forecast 函數視覺化
In [22]: results.plot_forecast(10)
Out[22]: <Figure size 1000x1000 with 3 Axes>
類別參考¶
|
擬合 VAR(p) 過程並執行落後期數選擇 |
|
類別表示已知的 VAR(p) 過程 |
|
使用固定滯後數估計 VAR(p) 過程 |
估計後分析¶
估計後,有幾個過程屬性和其他結果可用於向量自迴歸過程。
|
用於選擇模型滯後期數的結果類別。 |
|
假設檢定的結果類別。 |
|
用於非常態性 Jarque-Bera 檢定的結果類別。 |
|
殘差自相關 Portmanteau 檢定的結果類別。 |
脈衝響應分析¶
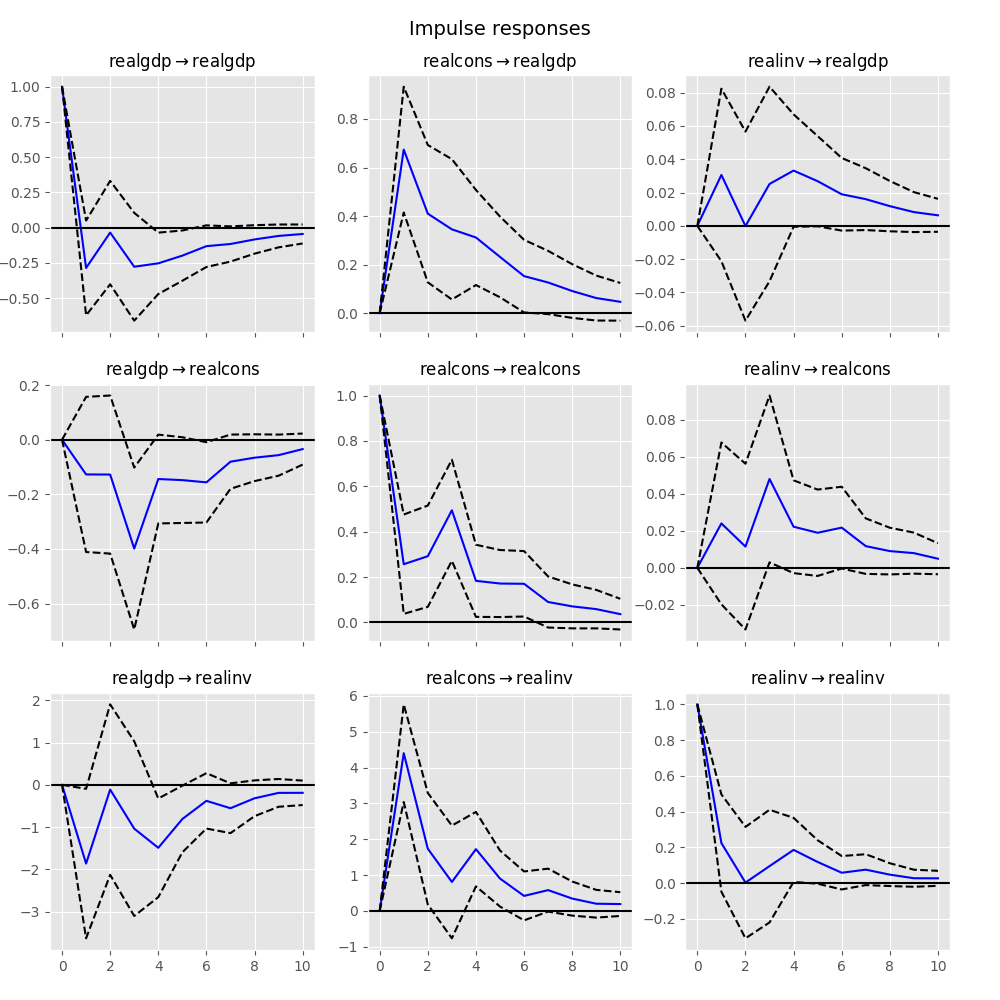
脈衝響應在計量經濟學研究中備受關注:它們是對其中一個變數的單位脈衝的估計響應。實際上,它們是使用 VAR(p) 過程的 MA(\(\infty\)) 表示法計算得出的。
我們可以透過在 VARResults 物件上呼叫 irf 函數來執行脈衝響應分析。
In [23]: irf = results.irf(10)
這些可以使用 plot 函數以正交化或非正交化的形式進行視覺化。預設會繪製 95% 顯著性水準的漸近標準誤差,使用者可以修改此水準。
注意
正交化是使用估計誤差共變異數矩陣 \(\hat \Sigma_u\) 的 Cholesky 分解來完成的,因此解釋可能會隨著變數順序而變化。
In [24]: irf.plot(orth=False)
Out[24]: <Figure size 1000x1000 with 9 Axes>
請注意,plot 函數很靈活,如果需要,可以只繪製感興趣的變數。
In [25]: irf.plot(impulse='realgdp')
Out[25]: <Figure size 1000x1000 with 3 Axes>
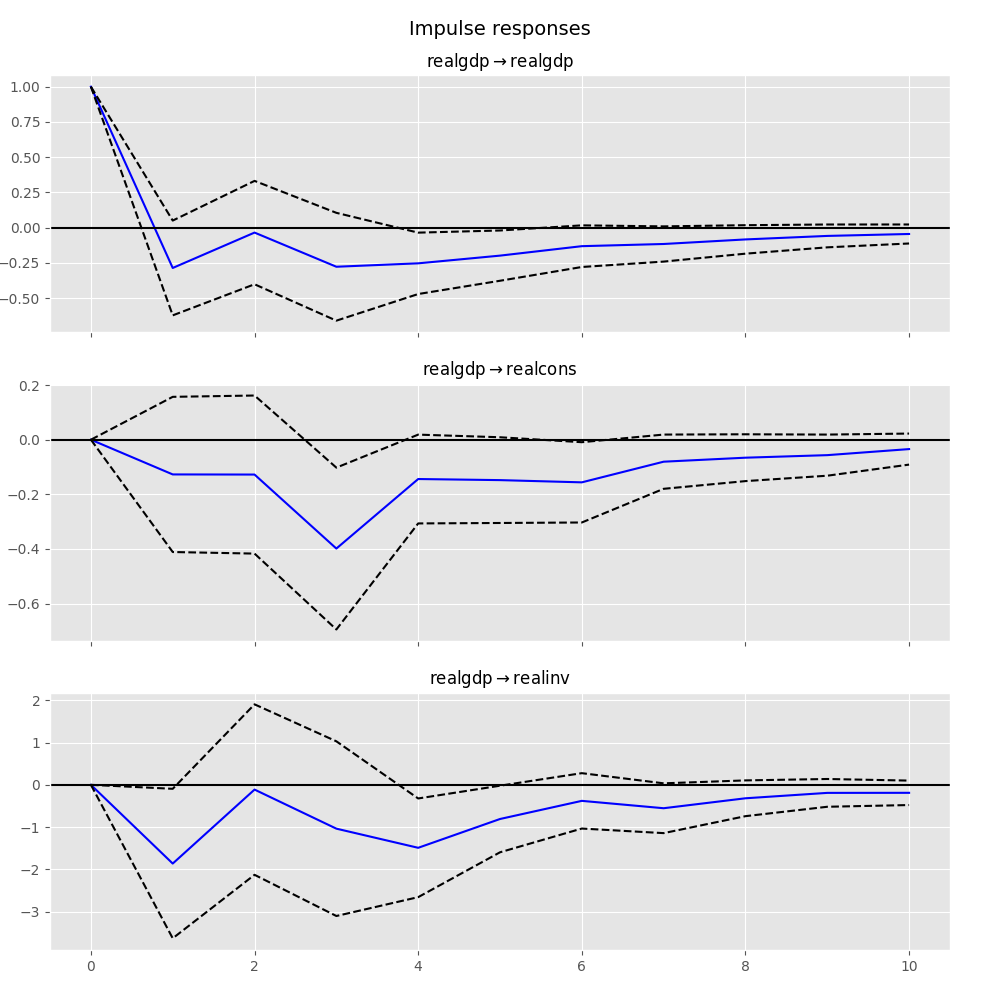
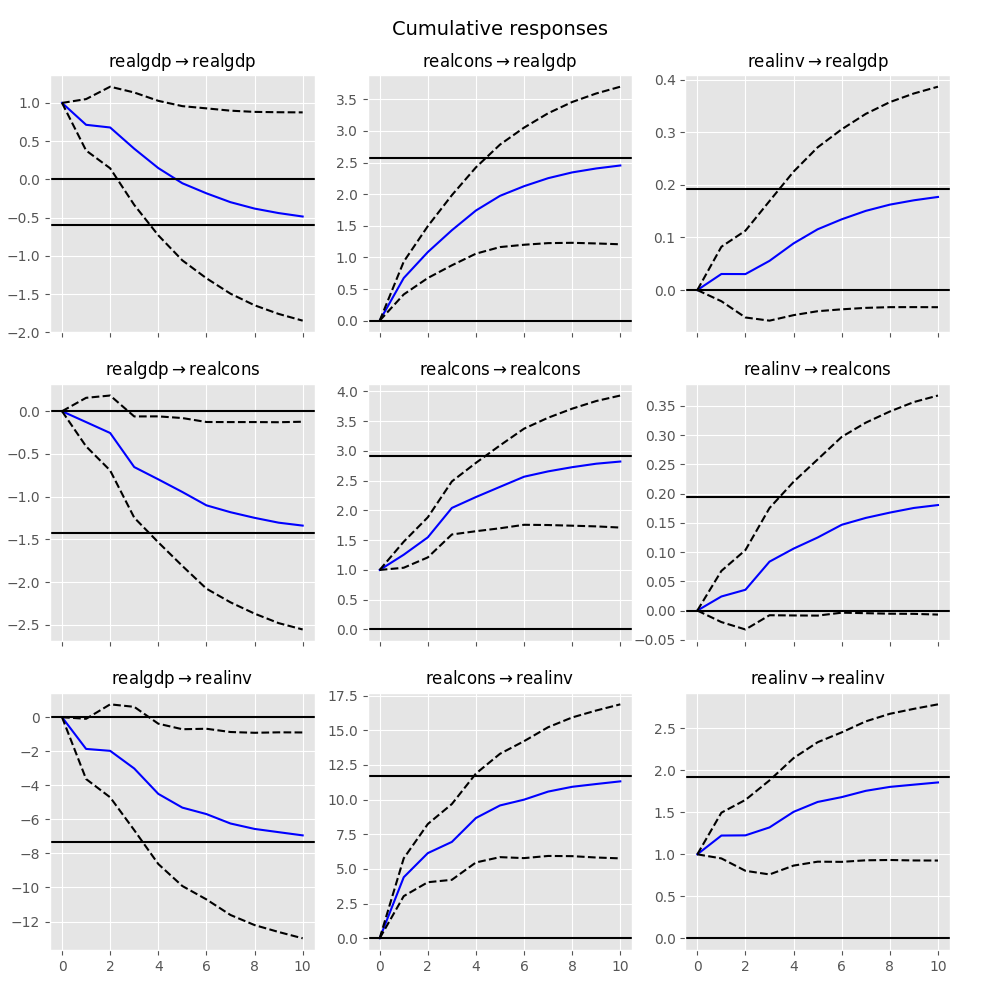
累計效果 \(\Psi_n = \sum_{i=0}^n \Phi_i\) 可以繪製長期的效果如下:
In [26]: irf.plot_cum_effects(orth=False)
Out[26]: <Figure size 1000x1000 with 9 Axes>
|
脈衝響應分析類別。 |
預測誤差變異數分解 (FEVD)¶
使用正交化脈衝響應 \(\Theta_i\),可以分解 i 步提前預測中元件 j 對 k 的預測誤差。
這些是透過 fevd 函數計算的,直到總共提前的步數為止。
In [27]: fevd = results.fevd(5)
In [28]: fevd.summary()
FEVD for realgdp
realgdp realcons realinv
0 1.000000 0.000000 0.000000
1 0.864889 0.129253 0.005858
2 0.816725 0.177898 0.005378
3 0.793647 0.197590 0.008763
4 0.777279 0.208127 0.014594
FEVD for realcons
realgdp realcons realinv
0 0.359877 0.640123 0.000000
1 0.358767 0.635420 0.005813
2 0.348044 0.645138 0.006817
3 0.319913 0.653609 0.026478
4 0.317407 0.652180 0.030414
FEVD for realinv
realgdp realcons realinv
0 0.577021 0.152783 0.270196
1 0.488158 0.293622 0.218220
2 0.478727 0.314398 0.206874
3 0.477182 0.315564 0.207254
4 0.466741 0.324135 0.209124
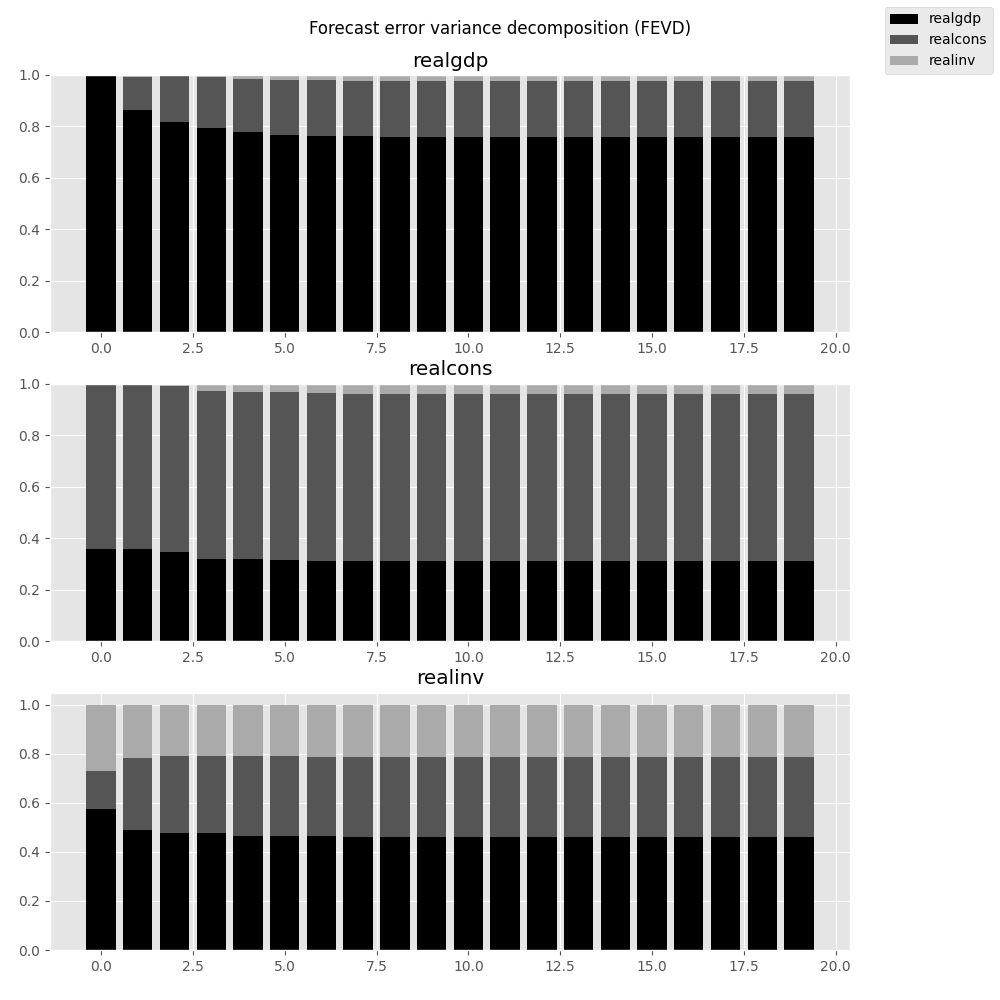
它們也可以透過傳回的 FEVD 物件進行視覺化。
In [29]: results.fevd(20).plot()
Out[29]: <Figure size 1000x1000 with 3 Axes>
|
計算和繪製預測誤差變異數分解和漸近標準誤差。 |
統計檢定¶
提供了一些不同的方法來執行關於模型結果的假設檢定,以及模型假設的有效性(常態性、殘差的白雜訊/「獨立同分佈性」等)。
Granger 因果關係¶
人們通常感興趣的是,對於「因果」的某些定義,一個或一組變數是否對另一個變數「有因果關係」。在 VAR 模型的情境中,可以說一組變數在其中一個 VAR 方程式中具有 Granger 因果關係。我們將不詳細說明 Granger 因果關係的數學或定義,而將其留給讀者自行研究。VARResults 物件具有 test_causality 方法,用於執行 Wald (\(\chi^2\)) 檢定或 F 檢定。
In [30]: results.test_causality('realgdp', ['realinv', 'realcons'], kind='f')
Out[30]: <statsmodels.tsa.vector_ar.hypothesis_test_results.CausalityTestResults at 0x7f18f3daf580>
常態性¶
如本文檔開頭所述,白雜訊分量 \(u_t\) 假設為常態分佈。雖然此假設並非參數估計值一致或漸近常態所必需,但當殘差為高斯白雜訊時,結果通常在有限樣本中更可靠。為了檢定此假設是否與數據集一致,VARResults 提供了 test_normality 方法。
In [31]: results.test_normality()
Out[31]: <statsmodels.tsa.vector_ar.hypothesis_test_results.NormalityTestResults at 0x7f18f3daf640>
殘差的白雜訊性¶
為了檢定估計殘差的白雜訊性(這表示不存在顯著的殘差自相關),可以使用 VARResults 的 test_whiteness 方法。
|
假設檢定的結果類別。 |
|
Granger 因果關係和瞬時因果關係的結果類別。 |
|
用於非常態性 Jarque-Bera 檢定的結果類別。 |
|
殘差自相關 Portmanteau 檢定的結果類別。 |
結構向量自迴歸 (SVAR)¶
有一組匹配的類別,可處理某些類型的結構 VAR 模型。
|
擬合 VAR,然後估計 A 和 B 的結構分量,定義為: |
|
類別表示已知的 SVAR(p) 過程。 |
|
使用固定滯後數估計 VAR(p) 過程 |
向量誤差修正模型 (VECM)¶
向量誤差修正模型用於研究一個或多個永久性隨機趨勢(單位根)的短期偏差。VECM 透過施加假設的隨機趨勢數量所暗示的結構,對時間序列向量的差分進行建模。VECM 用於指定和估計這些模型。
VECM(\(k_{ar}-1\)) 的形式如下:
其中
如 [1] 的第 7 章所述。
具有確定性項的 VECM(\(k_{ar} - 1\)) 的形式為:
在 \(D^{co}_{t-1}\) 中,我們有在共整合關係內部(或限制在共整合關係中)的確定性項。\(\eta\) 是對應的估計量。為了將確定性項傳遞到共整合關係內部,我們可以使用 exog_coint 引數。對於截距和線性趨勢這兩種特殊情況,存在一種更簡單的方法來宣告這些項:我們可以分別將 "ci" 和 "li" 傳遞給 deterministic 引數。因此,對於共整合關係內部的截距,如果 data 作為 endog 引數傳遞,我們可以將 "ci" 作為 deterministic 傳遞,或者將 np.ones(len(data)) 作為 exog_coint 傳遞。這確保對於所有 \(t\),\(D_{t-1}^{co} = 1\)。
我們也可以在共整合關係之外使用確定性項。這些在上面的公式中定義為 \(D_t\),對應的估計量在矩陣 \(C\) 中。我們透過將它們傳遞給 exog 引數來指定此類項。對於截距和/或線性趨勢,我們再次可以使用 deterministic 作為替代方法。對於截距,我們傳遞 "co",對於線性趨勢,我們傳遞 "lo",其中 o 代表 outside(外部)。
下表顯示了 [2] 中考慮的五種情況。最後一列指示在這些情況中,要傳遞給 deterministic 引數的字串。
情況 |
截距 |
線性趨勢的斜率 |
deterministic |
|---|---|---|---|
I |
0 |
0 |
|
II |
\(- \alpha \beta^T \mu\) |
0 |
|
III |
\(\neq 0\) |
0 |
|
IV |
\(\neq 0\) |
\(- \alpha \beta^T \gamma\) |
|
V |
\(\neq 0\) |
\(\neq 0\) |
|
|
表示向量誤差修正模型(VECM)的類別。 |
|
對 VECM 的共整合階數進行 Johansen 共整合檢定。 |
|
Johansen 共整合檢定的結果類別。 |
|
根據每個可用的資訊準則計算滯後階數的選擇。 |
|
計算 VECM 的共整合階數。 |
|
用於保存向量誤差修正模型(VECM)估計相關結果的類別。 |
|
用於保存共整合階數檢定結果的類別。 |