迴歸診斷¶
此範例檔案展示如何在實際情境中使用幾個 statsmodels 迴歸診斷檢定。您可以在迴歸診斷頁面上了解更多關於檢定的資訊。
請注意,這裡描述的大多數檢定只會回傳一個數字的元組,而沒有任何註解。輸出的完整描述始終包含在 docstring 和線上 statsmodels 文件中。為了呈現的目的,我們使用 zip(name,test) 結構在下面的範例中漂亮地印出簡短的描述。
估計迴歸模型¶
[1]:
%matplotlib inline
[2]:
from statsmodels.compat import lzip
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import statsmodels.stats.api as sms
import matplotlib.pyplot as plt
# Load data
url = "https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/HistData/Guerry.csv"
dat = pd.read_csv(url)
# Fit regression model (using the natural log of one of the regressors)
results = smf.ols("Lottery ~ Literacy + np.log(Pop1831)", data=dat).fit()
# Inspect the results
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Lottery R-squared: 0.348
Model: OLS Adj. R-squared: 0.333
Method: Least Squares F-statistic: 22.20
Date: Thu, 03 Oct 2024 Prob (F-statistic): 1.90e-08
Time: 16:05:44 Log-Likelihood: -379.82
No. Observations: 86 AIC: 765.6
Df Residuals: 83 BIC: 773.0
Df Model: 2
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept 246.4341 35.233 6.995 0.000 176.358 316.510
Literacy -0.4889 0.128 -3.832 0.000 -0.743 -0.235
np.log(Pop1831) -31.3114 5.977 -5.239 0.000 -43.199 -19.424
==============================================================================
Omnibus: 3.713 Durbin-Watson: 2.019
Prob(Omnibus): 0.156 Jarque-Bera (JB): 3.394
Skew: -0.487 Prob(JB): 0.183
Kurtosis: 3.003 Cond. No. 702.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
殘差的常態性¶
Jarque-Bera 檢定
[3]:
name = ["Jarque-Bera", "Chi^2 two-tail prob.", "Skew", "Kurtosis"]
test = sms.jarque_bera(results.resid)
lzip(name, test)
[3]:
[('Jarque-Bera', np.float64(3.39360802484318)),
('Chi^2 two-tail prob.', np.float64(0.18326831231663254)),
('Skew', np.float64(-0.4865803431122347)),
('Kurtosis', np.float64(3.003417757881634))]
Omni 檢定
[4]:
name = ["Chi^2", "Two-tail probability"]
test = sms.omni_normtest(results.resid)
lzip(name, test)
[4]:
[('Chi^2', np.float64(3.7134378115971933)),
('Two-tail probability', np.float64(0.15618424580304735))]
影響力檢定¶
一旦創建完成,類別為 OLSInfluence 的物件會持有屬性和方法,讓使用者評估每個觀察值的影響力。例如,我們可以透過以下方式計算並提取 DFbetas 的前幾列
[5]:
from statsmodels.stats.outliers_influence import OLSInfluence
test_class = OLSInfluence(results)
test_class.dfbetas[:5, :]
[5]:
array([[-0.00301154, 0.00290872, 0.00118179],
[-0.06425662, 0.04043093, 0.06281609],
[ 0.01554894, -0.03556038, -0.00905336],
[ 0.17899858, 0.04098207, -0.18062352],
[ 0.29679073, 0.21249207, -0.3213655 ]])
輸入 dir(influence_test) 來探索其他選項
關於槓桿作用的有用資訊也可以繪製出來
[6]:
from statsmodels.graphics.regressionplots import plot_leverage_resid2
fig, ax = plt.subplots(figsize=(8, 6))
fig = plot_leverage_resid2(results, ax=ax)
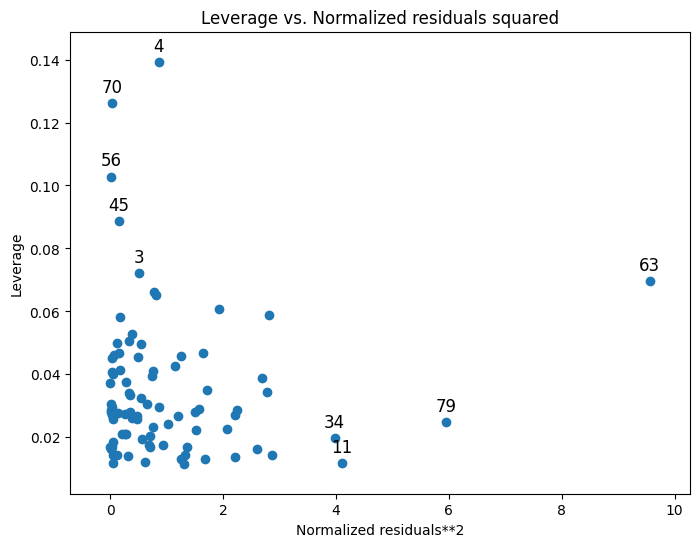
其他繪圖選項可以在繪圖頁面上找到。
多重共線性¶
條件數
[7]:
np.linalg.cond(results.model.exog)
[7]:
np.float64(702.1792145490066)
異質變異數檢定¶
Breush-Pagan 檢定
[8]:
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_breuschpagan(results.resid, results.model.exog)
lzip(name, test)
[8]:
[('Lagrange multiplier statistic', np.float64(4.893213374094005)),
('p-value', np.float64(0.08658690502352002)),
('f-value', np.float64(2.5037159462564618)),
('f p-value', np.float64(0.08794028782672814))]
Goldfeld-Quandt 檢定
[9]:
name = ["F statistic", "p-value"]
test = sms.het_goldfeldquandt(results.resid, results.model.exog)
lzip(name, test)
[9]:
[('F statistic', np.float64(1.1002422436378143)),
('p-value', np.float64(0.38202950686925324))]
線性¶
Harvey-Collier 乘數檢定,用於檢定線性規格是否正確的虛無假設
[10]:
name = ["t value", "p value"]
test = sms.linear_harvey_collier(results)
lzip(name, test)
[10]:
[('t value', np.float64(-1.0796490077759802)),
('p value', np.float64(0.2834639247569222))]
上次更新:2024 年 10 月 03 日