使用 LOESS 的季節性趨勢分解 (STL)¶
本筆記本說明如何使用 STL 將時間序列分解為三個組成部分:趨勢、季節性(或季節)和殘差。STL 使用 LOESS(局部加權散佈圖平滑)來提取三個組成部分的平滑估計值。STL 的主要輸入是
season- 季節性平滑器的長度。必須為奇數。trend- 趨勢平滑器的長度,通常約為season的 150%。必須為奇數且大於season。low_pass- 低通估計視窗的長度,通常是比數據週期性大的最小奇數。
首先,我們匯入所需的套件,準備圖形環境,並準備數據。
[1]:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()
sns.set_style("darkgrid")
[2]:
plt.rc("figure", figsize=(16, 12))
plt.rc("font", size=13)
大氣中的二氧化碳¶
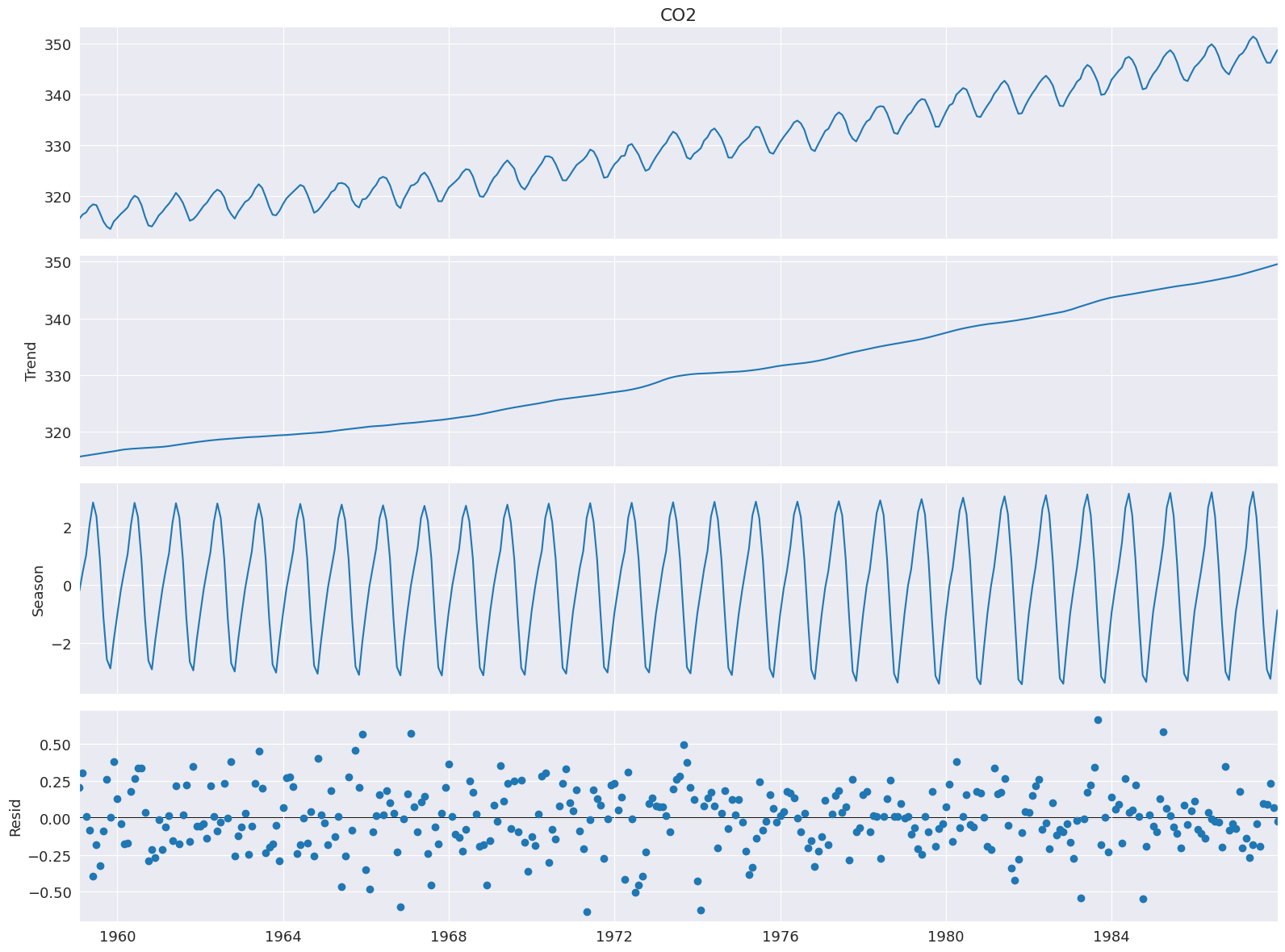
Cleveland, Cleveland, McRae 和 Terpenning (1990) 中的範例使用二氧化碳數據,該數據在下面的列表中。這個每月數據(1959 年 1 月至 1987 年 12 月)在整個樣本中具有明顯的趨勢和季節性。
[3]:
co2 = [
315.58,
316.39,
316.79,
317.82,
318.39,
318.22,
316.68,
315.01,
314.02,
313.55,
315.02,
315.75,
316.52,
317.10,
317.79,
319.22,
320.08,
319.70,
318.27,
315.99,
314.24,
314.05,
315.05,
316.23,
316.92,
317.76,
318.54,
319.49,
320.64,
319.85,
318.70,
316.96,
315.17,
315.47,
316.19,
317.17,
318.12,
318.72,
319.79,
320.68,
321.28,
320.89,
319.79,
317.56,
316.46,
315.59,
316.85,
317.87,
318.87,
319.25,
320.13,
321.49,
322.34,
321.62,
319.85,
317.87,
316.36,
316.24,
317.13,
318.46,
319.57,
320.23,
320.89,
321.54,
322.20,
321.90,
320.42,
318.60,
316.73,
317.15,
317.94,
318.91,
319.73,
320.78,
321.23,
322.49,
322.59,
322.35,
321.61,
319.24,
318.23,
317.76,
319.36,
319.50,
320.35,
321.40,
322.22,
323.45,
323.80,
323.50,
322.16,
320.09,
318.26,
317.66,
319.47,
320.70,
322.06,
322.23,
322.78,
324.10,
324.63,
323.79,
322.34,
320.73,
319.00,
318.99,
320.41,
321.68,
322.30,
322.89,
323.59,
324.65,
325.30,
325.15,
323.88,
321.80,
319.99,
319.86,
320.88,
322.36,
323.59,
324.23,
325.34,
326.33,
327.03,
326.24,
325.39,
323.16,
321.87,
321.31,
322.34,
323.74,
324.61,
325.58,
326.55,
327.81,
327.82,
327.53,
326.29,
324.66,
323.12,
323.09,
324.01,
325.10,
326.12,
326.62,
327.16,
327.94,
329.15,
328.79,
327.53,
325.65,
323.60,
323.78,
325.13,
326.26,
326.93,
327.84,
327.96,
329.93,
330.25,
329.24,
328.13,
326.42,
324.97,
325.29,
326.56,
327.73,
328.73,
329.70,
330.46,
331.70,
332.66,
332.22,
331.02,
329.39,
327.58,
327.27,
328.30,
328.81,
329.44,
330.89,
331.62,
332.85,
333.29,
332.44,
331.35,
329.58,
327.58,
327.55,
328.56,
329.73,
330.45,
330.98,
331.63,
332.88,
333.63,
333.53,
331.90,
330.08,
328.59,
328.31,
329.44,
330.64,
331.62,
332.45,
333.36,
334.46,
334.84,
334.29,
333.04,
330.88,
329.23,
328.83,
330.18,
331.50,
332.80,
333.22,
334.54,
335.82,
336.45,
335.97,
334.65,
332.40,
331.28,
330.73,
332.05,
333.54,
334.65,
335.06,
336.32,
337.39,
337.66,
337.56,
336.24,
334.39,
332.43,
332.22,
333.61,
334.78,
335.88,
336.43,
337.61,
338.53,
339.06,
338.92,
337.39,
335.72,
333.64,
333.65,
335.07,
336.53,
337.82,
338.19,
339.89,
340.56,
341.22,
340.92,
339.26,
337.27,
335.66,
335.54,
336.71,
337.79,
338.79,
340.06,
340.93,
342.02,
342.65,
341.80,
340.01,
337.94,
336.17,
336.28,
337.76,
339.05,
340.18,
341.04,
342.16,
343.01,
343.64,
342.91,
341.72,
339.52,
337.75,
337.68,
339.14,
340.37,
341.32,
342.45,
343.05,
344.91,
345.77,
345.30,
343.98,
342.41,
339.89,
340.03,
341.19,
342.87,
343.74,
344.55,
345.28,
347.00,
347.37,
346.74,
345.36,
343.19,
340.97,
341.20,
342.76,
343.96,
344.82,
345.82,
347.24,
348.09,
348.66,
347.90,
346.27,
344.21,
342.88,
342.58,
343.99,
345.31,
345.98,
346.72,
347.63,
349.24,
349.83,
349.10,
347.52,
345.43,
344.48,
343.89,
345.29,
346.54,
347.66,
348.07,
349.12,
350.55,
351.34,
350.80,
349.10,
347.54,
346.20,
346.20,
347.44,
348.67,
]
co2 = pd.Series(
co2, index=pd.date_range("1-1-1959", periods=len(co2), freq="M"), name="CO2"
)
co2.describe()
/tmp/ipykernel_3881/1071343913.py:352: FutureWarning: 'M' is deprecated and will be removed in a future version, please use 'ME' instead.
co2, index=pd.date_range("1-1-1959", periods=len(co2), freq="M"), name="CO2"
[3]:
count 348.000000
mean 330.123879
std 10.059747
min 313.550000
25% 321.302500
50% 328.820000
75% 338.002500
max 351.340000
Name: CO2, dtype: float64
分解需要 1 個輸入,即數據序列。如果數據序列沒有頻率,則還必須指定 period。seasonal 的預設值為 7,因此在大多數應用中也應更改。
[4]:
from statsmodels.tsa.seasonal import STL
stl = STL(co2, seasonal=13)
res = stl.fit()
fig = res.plot()
穩健擬合¶
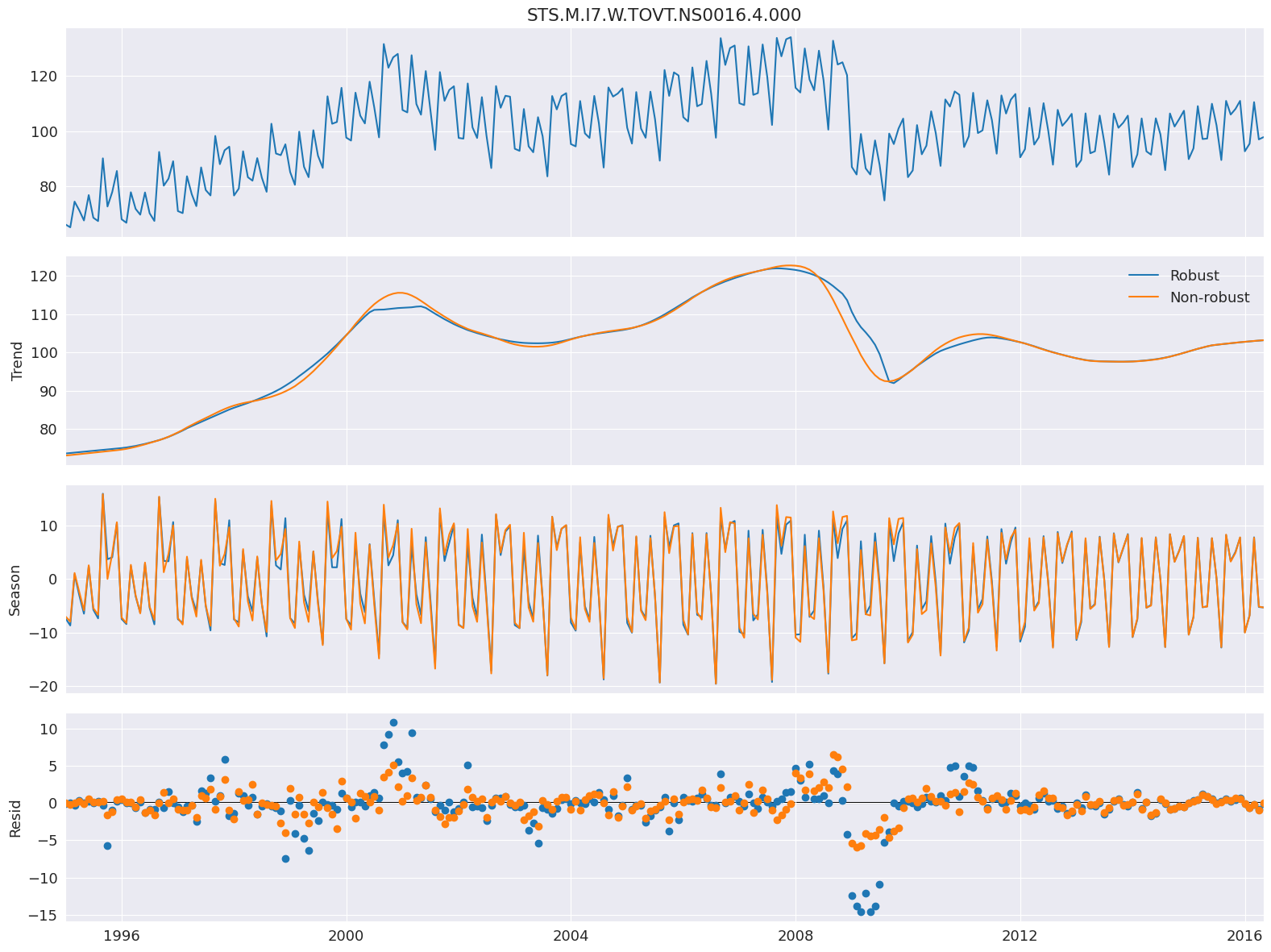
設定 robust 會使用與數據相關的加權函數,在估計 LOESS 時重新加權數據(因此使用 LOWESS)。使用穩健估計可以讓模型容忍底部圖中可見的較大誤差。
在這裡,我們使用一個衡量歐盟電氣設備產量的序列。
[5]:
from statsmodels.datasets import elec_equip as ds
elec_equip = ds.load().data.iloc[:, 0]
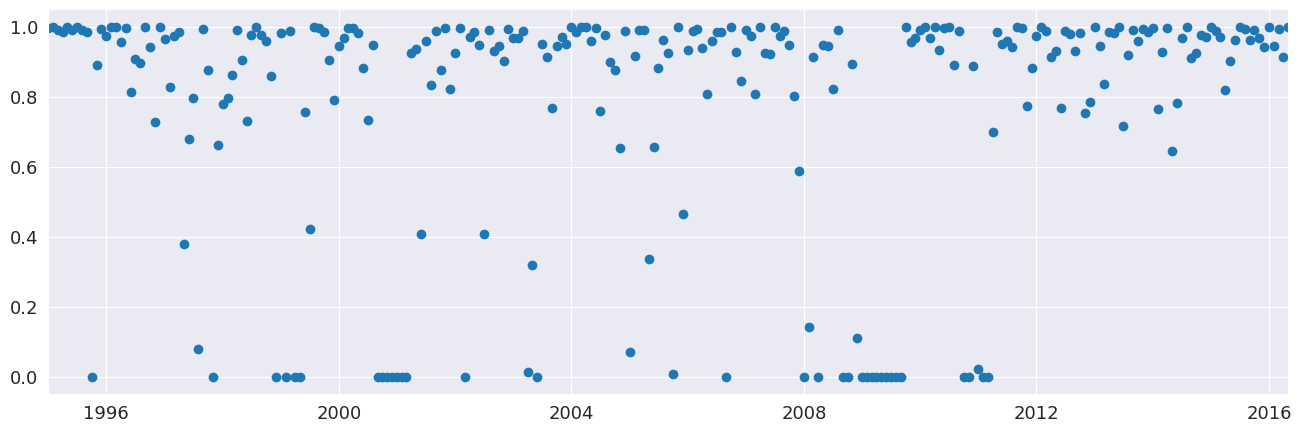
接下來,我們估計有和沒有穩健加權的模型。差異很小,在 2008 年的金融危機期間最為明顯。非穩健估計會對所有觀測值給予相同的權重,因此平均會產生較小的誤差。權重在 0 和 1 之間變化。
[6]:
def add_stl_plot(fig, res, legend):
"""Add 3 plots from a second STL fit"""
axs = fig.get_axes()
comps = ["trend", "seasonal", "resid"]
for ax, comp in zip(axs[1:], comps):
series = getattr(res, comp)
if comp == "resid":
ax.plot(series, marker="o", linestyle="none")
else:
ax.plot(series)
if comp == "trend":
ax.legend(legend, frameon=False)
stl = STL(elec_equip, period=12, robust=True)
res_robust = stl.fit()
fig = res_robust.plot()
res_non_robust = STL(elec_equip, period=12, robust=False).fit()
add_stl_plot(fig, res_non_robust, ["Robust", "Non-robust"])
[7]:
fig = plt.figure(figsize=(16, 5))
lines = plt.plot(res_robust.weights, marker="o", linestyle="none")
ax = plt.gca()
xlim = ax.set_xlim(elec_equip.index[0], elec_equip.index[-1])
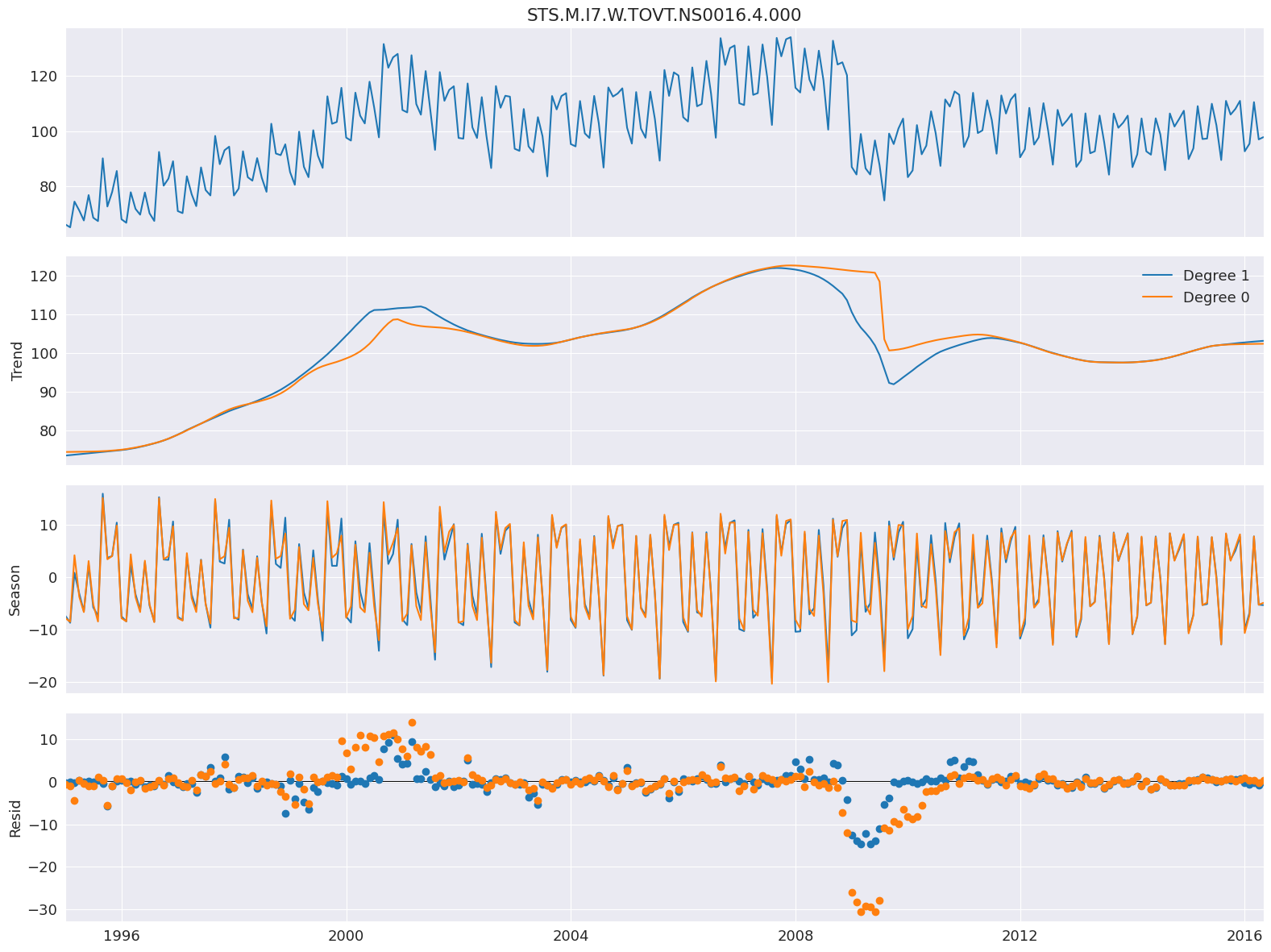
LOESS 次數¶
預設設定會使用常數和趨勢估計 LOESS 模型。可以將其更改為僅包含常數,方法是將 COMPONENT_deg 設定為 0。這裡的次數除了在 2008 年金融危機附近的趨勢之外,幾乎沒有差別。
[8]:
stl = STL(
elec_equip, period=12, seasonal_deg=0, trend_deg=0, low_pass_deg=0, robust=True
)
res_deg_0 = stl.fit()
fig = res_robust.plot()
add_stl_plot(fig, res_deg_0, ["Degree 1", "Degree 0"])
效能¶
可以使用三個選項來降低 STL 分解的計算成本
seasonal_jumptrend_jumplow_pass_jump
當這些值不為零時,僅在每 COMPONENT_jump 個觀測值處估計成分 COMPONENT 的 LOESS,並且在點之間使用線性內插。這些值通常不應超過 seasonal、trend 或 low_pass 大小的 10-20%。
下面的範例顯示如何使用具有低頻餘弦趨勢和正弦季節性模式的模擬數據,將計算成本降低 15 倍。
[9]:
import numpy as np
rs = np.random.RandomState(0xA4FD94BC)
tau = 2000
t = np.arange(tau)
period = int(0.05 * tau)
seasonal = period + ((period % 2) == 0) # Ensure odd
e = 0.25 * rs.standard_normal(tau)
y = np.cos(t / tau * 2 * np.pi) + 0.25 * np.sin(t / period * 2 * np.pi) + e
plt.plot(y)
plt.title("Simulated Data")
xlim = plt.gca().set_xlim(0, tau)
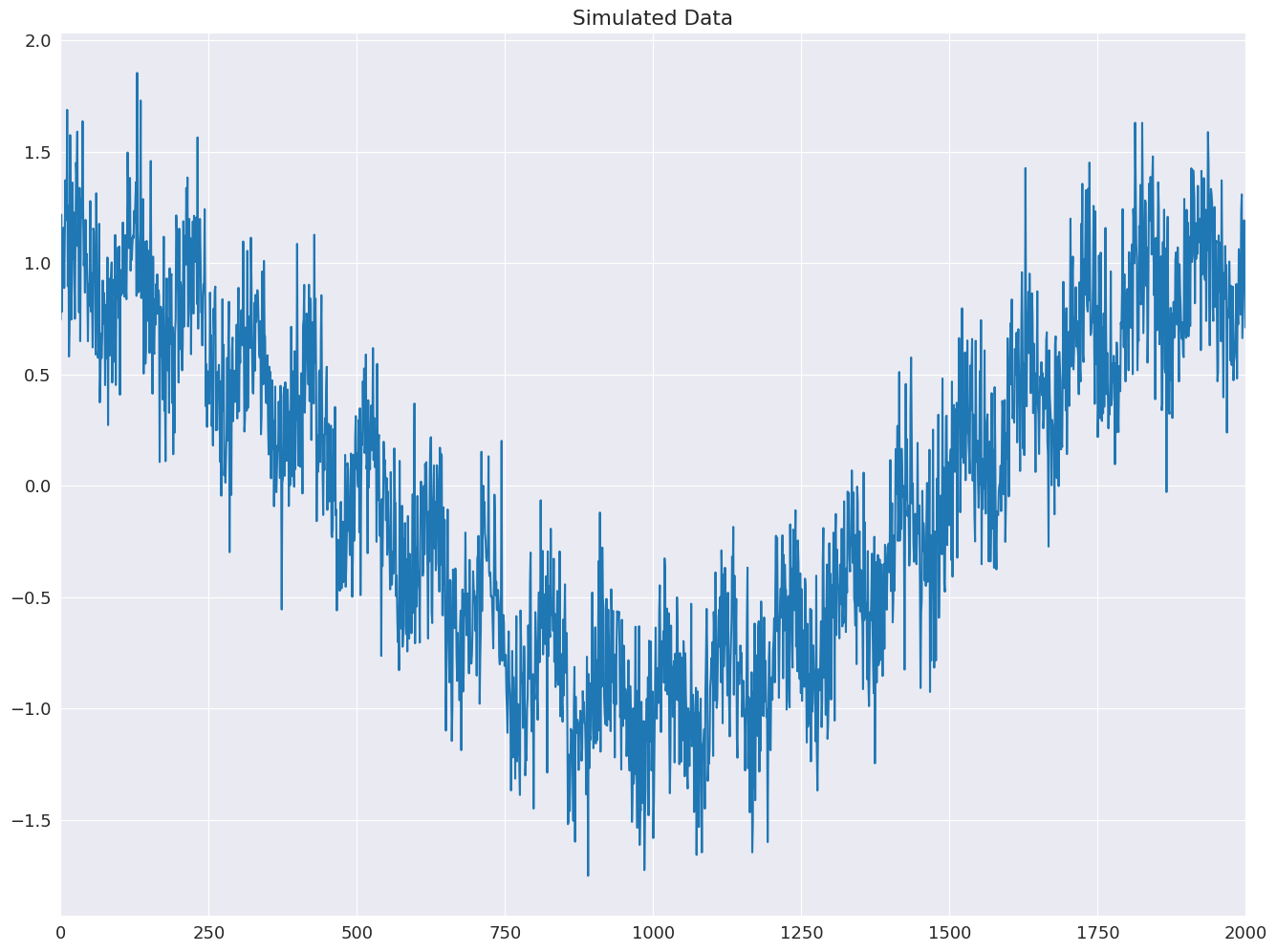
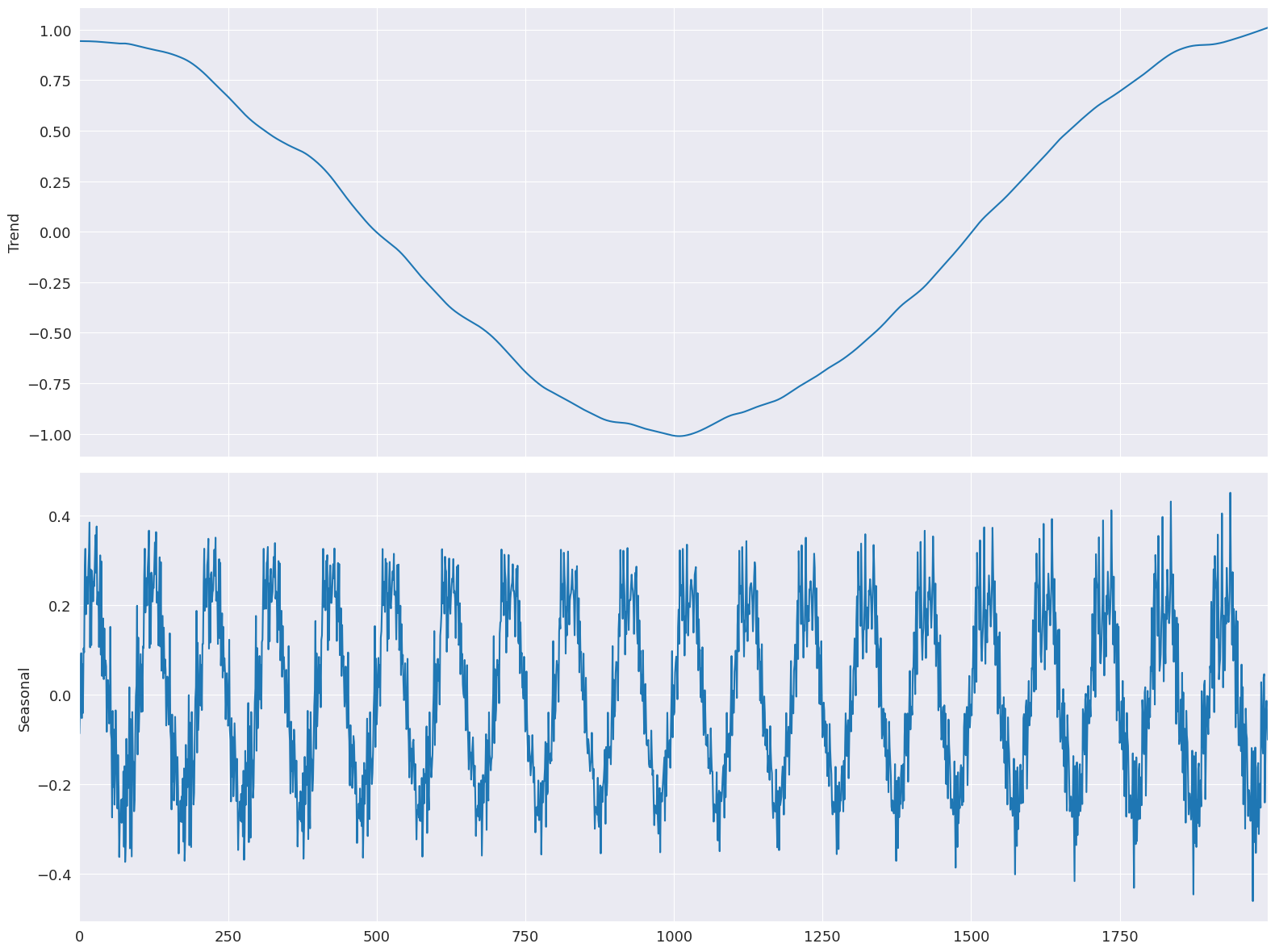
首先,估計所有跳躍都等於 1 的基準模型。
[10]:
mod = STL(y, period=period, seasonal=seasonal)
%timeit mod.fit()
res = mod.fit()
fig = res.plot(observed=False, resid=False)
284 ms ± 38.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
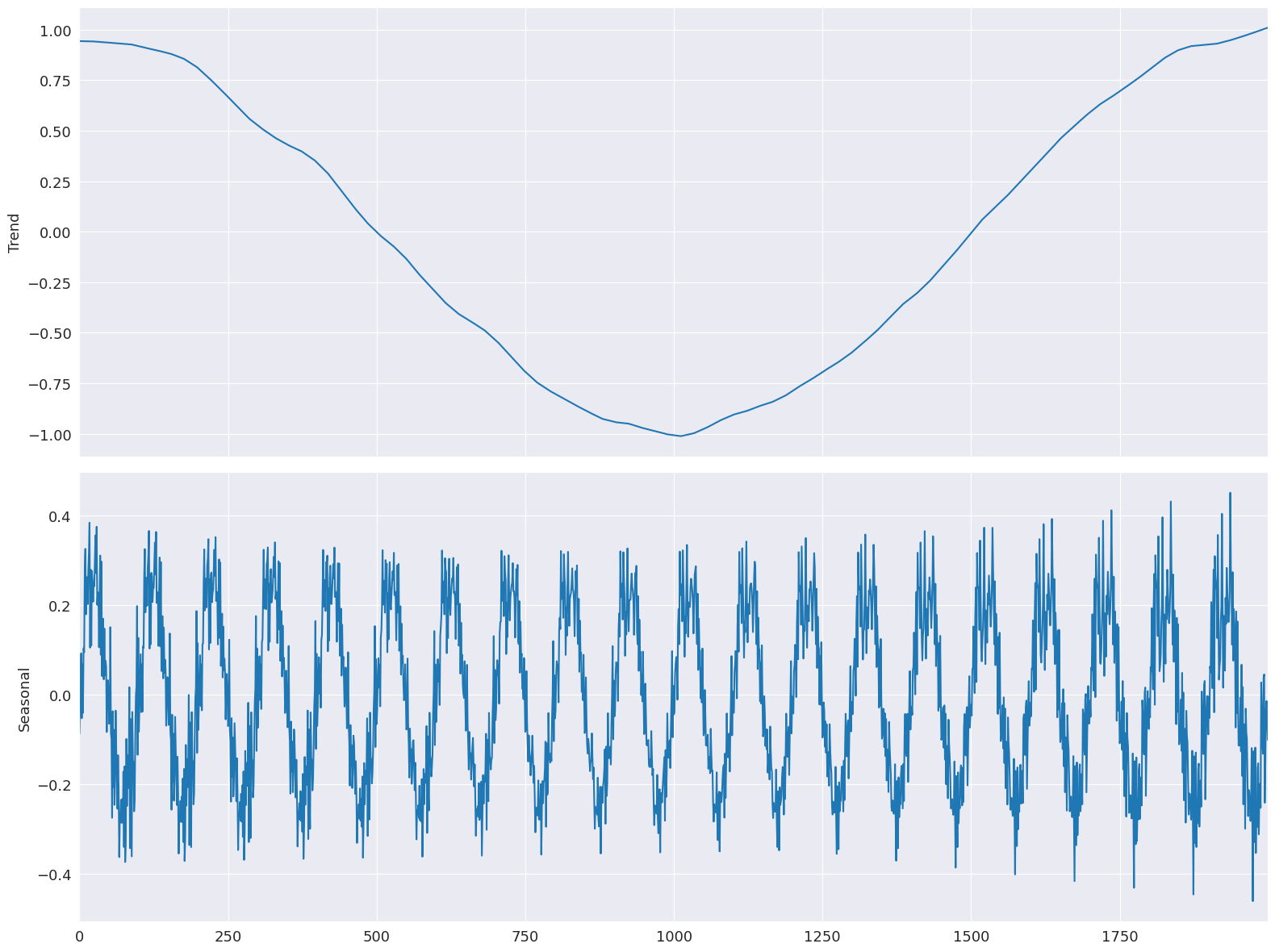
跳躍全部設定為其視窗長度的 15%。有限的線性內插對模型的擬合影響不大。
[11]:
low_pass_jump = seasonal_jump = int(0.15 * (period + 1))
trend_jump = int(0.15 * 1.5 * (period + 1))
mod = STL(
y,
period=period,
seasonal=seasonal,
seasonal_jump=seasonal_jump,
trend_jump=trend_jump,
low_pass_jump=low_pass_jump,
)
%timeit mod.fit()
res = mod.fit()
fig = res.plot(observed=False, resid=False)
22.9 ms ± 1.04 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
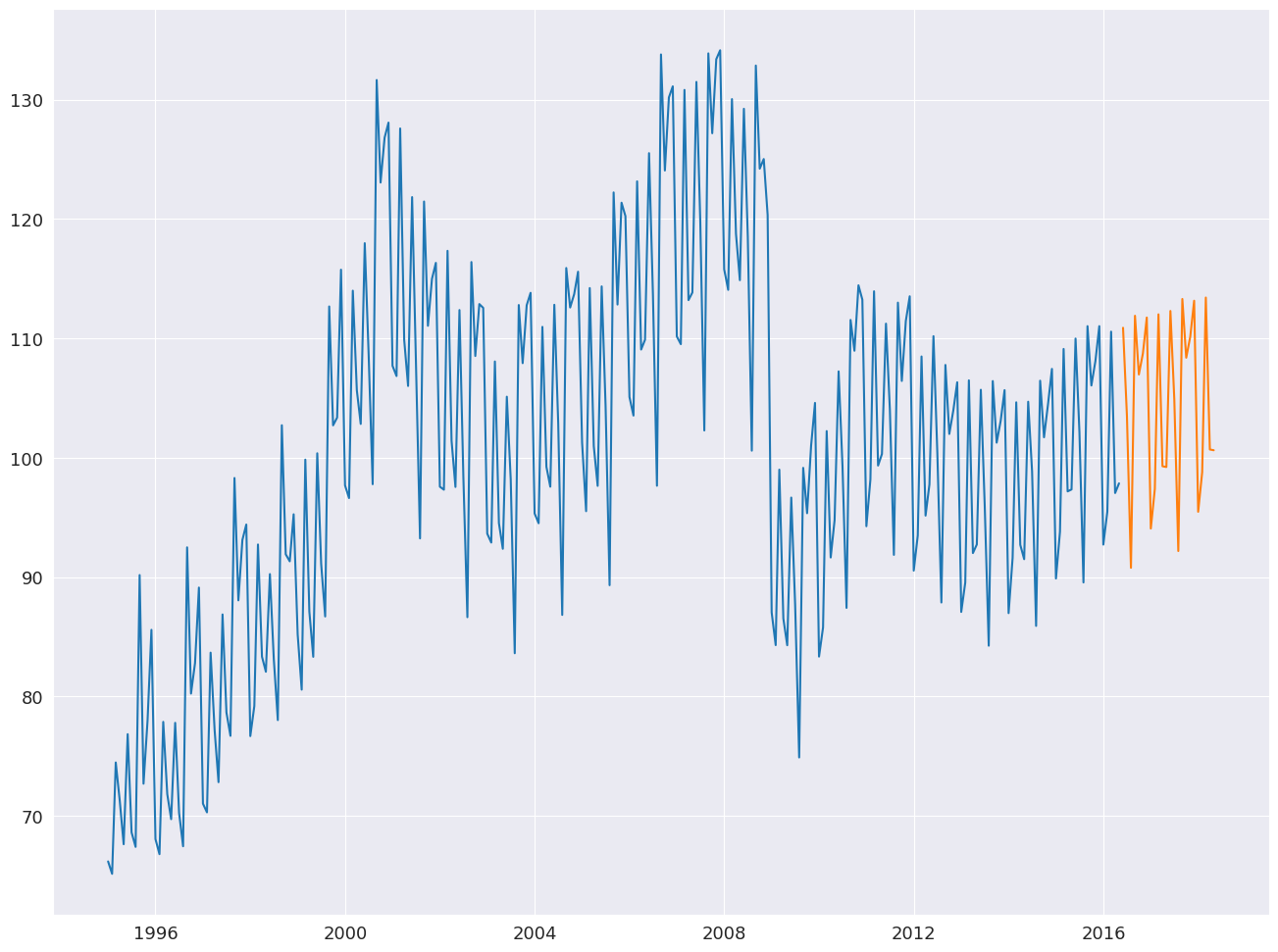
使用 STL 進行預測¶
STLForecast 簡化了使用 STL 移除季節性,然後使用標準時間序列模型預測趨勢和循環成分的過程。
在這裡,我們使用 STL 來處理季節性,然後使用 ARIMA(1,1,0) 來建模去除季節性的數據。季節性成分是從找到完整週期的位置預測的,其中
其中 \(k= m - h + m \lfloor \frac{h-1}{m} \rfloor\)。預測會自動將季節性成分預測新增到 ARIMA 預測中。
[12]:
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.forecasting.stl import STLForecast
elec_equip.index.freq = elec_equip.index.inferred_freq
stlf = STLForecast(elec_equip, ARIMA, model_kwargs=dict(order=(1, 1, 0), trend="t"))
stlf_res = stlf.fit()
forecast = stlf_res.forecast(24)
plt.plot(elec_equip)
plt.plot(forecast)
plt.show()
summary 包含有關時間序列模型和 STL 分解的資訊。
[13]:
print(stlf_res.summary())
STL Decomposition and SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 257
Model: ARIMA(1, 1, 0) Log Likelihood -522.434
Date: Thu, 03 Oct 2024 AIC 1050.868
Time: 15:45:57 BIC 1061.504
Sample: 01-01-1995 HQIC 1055.146
- 05-01-2016
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
x1 0.1171 0.118 0.995 0.320 -0.113 0.348
ar.L1 -0.0435 0.049 -0.880 0.379 -0.140 0.053
sigma2 3.4682 0.188 18.406 0.000 3.099 3.837
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 223.01
Prob(Q): 0.92 Prob(JB): 0.00
Heteroskedasticity (H): 0.33 Skew: -0.26
Prob(H) (two-sided): 0.00 Kurtosis: 7.54
STL Configuration
=================================================================================
Period: 12 Trend Length: 23
Seasonal: 7 Trend deg: 1
Seasonal deg: 1 Trend jump: 1
Seasonal jump: 1 Low pass: 13
Robust: False Low pass deg: 1
---------------------------------------------------------------------------------
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).