去除趨勢、典型化事實與景氣循環¶
在一篇具影響力的文章中,Harvey 和 Jaeger (1993) 描述了使用未觀察到的成分模型(也稱為「結構時間序列模型」)來推導景氣循環的典型化事實。
他們的論文開頭是:
"Establishing the 'stylized facts' associated with a set of time series is widely considered a crucial step
in macroeconomic research ... For such facts to be useful they should (1) be consistent with the stochastic
properties of the data and (2) present meaningful information."
特別是,他們主張,使用未觀察到的成分方法,通常比使用流行的 Hodrick-Prescott 濾波器或 Box-Jenkins ARIMA 建模技術,更能實現這些目標。
statsmodels 具有執行所有三種類型分析的能力,以下我們將按照他們論文中的步驟,使用稍微更新的資料集。
[1]:
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
from IPython.display import display, Latex
未觀察到的成分¶
statsmodels 中可用的未觀察到的成分模型可以寫成
請參閱 Durbin 和 Koopman 2012 年第 3 章,了解符號和更多詳細資訊。請注意,不同個別成分的不同規範可以支援各種模型。論文中和以下考慮的特定模型是這個一般方程式的特例。
趨勢¶
趨勢成分是迴歸模型的動態擴展,其中包括截距和線性時間趨勢。
其中,水準是截距項的推廣,可以在時間上動態變化,而趨勢是時間趨勢的推廣,使得斜率可以在時間上動態變化。
對於水準和趨勢這兩個元素,我們可以考慮以下模型:
是否包含該元素(如果包含趨勢,則也必須包含水準)。
該元素是確定性的還是隨機性的(即誤差項的變異數是否被限制為零)。
透過 MLE 估計的唯一額外參數是任何包含的隨機成分的變異數。
這導致以下規範:
水準 |
趨勢 |
隨機水準 |
隨機趨勢 |
|
|---|---|---|---|---|
常數 |
✓ |
|||
局部水準(隨機漫步) |
✓ |
✓ |
||
確定性趨勢 |
✓ |
✓ |
||
具有確定性趨勢的局部水準(具有漂移的隨機漫步) |
✓ |
✓ |
✓ |
|
局部線性趨勢 |
✓ |
✓ |
✓ |
✓ |
平滑趨勢(整合隨機漫步) |
✓ |
✓ |
✓ |
季節性¶
季節性成分寫為
週期性(季節數)為 s,其定義特徵是(沒有誤差項),季節性成分在一個完整週期內總和為零。包含誤差項允許季節性效應隨時間變化。
此模型的變體包括
週期性
s是否使季節性效應具有隨機性。
如果季節性效應是隨機的,則有一個額外的參數可以透過 MLE 估計(誤差項的變異數)。
循環¶
循環成分旨在捕獲時間範圍比季節性成分長得多的循環效應。例如,在經濟學中,循環項通常旨在捕獲景氣循環,因此預計週期在「1.5 到 12 年之間」(請參閱 Durbin 和 Koopman)。
循環寫為
參數 \(\lambda_c\) (循環的頻率)是另一個要透過 MLE 估計的參數。如果季節性效應是隨機的,則還有另一個參數要估計(誤差項的變異數 - 請注意,這裡的兩個誤差項共享相同的變異數,但假設具有獨立的抽樣)。
不規則¶
假設不規則成分是白雜訊誤差項。其變異數是要透過 MLE 估計的參數;即
在某些情況下,我們可能希望推廣不規則成分以允許自迴歸效應
在這種情況下,自迴歸參數也將透過 MLE 估計。
迴歸效應¶
我們可能希望透過包含其他項來允許解釋變數
或透過包含以下項來表示介入效應
這些額外參數可以透過 MLE 估計,也可以將其包含為狀態空間公式的成分。
資料¶
根據 Harvey 和 Jaeger 的研究,我們將考慮以下時間序列
原始論文中的時間範圍因序列而異,但大致為 1954-1989 年。以下我們使用 1948-2008 年期間所有序列的資料。雖然未觀察到的成分方法允許在模型中隔離季節性成分,但論文中以及這裡考慮的序列已經過季節性調整。
這裡考慮的所有資料序列都取自聯邦準備經濟資料 (FRED)。方便的是,Python 函式庫 Pandas 能夠直接從 FRED 下載資料。
[2]:
# Datasets
from pandas_datareader.data import DataReader
# Get the raw data
start = '1948-01'
end = '2008-01'
us_gnp = DataReader('GNPC96', 'fred', start=start, end=end)
us_gnp_deflator = DataReader('GNPDEF', 'fred', start=start, end=end)
us_monetary_base = DataReader('AMBSL', 'fred', start=start, end=end).resample('QS').mean()
recessions = DataReader('USRECQ', 'fred', start=start, end=end).resample('QS').last().values[:,0]
# Construct the dataframe
dta = pd.concat(map(np.log, (us_gnp, us_gnp_deflator, us_monetary_base)), axis=1)
dta.columns = ['US GNP','US Prices','US monetary base']
dta.index.freq = dta.index.inferred_freq
dates = dta.index._mpl_repr()
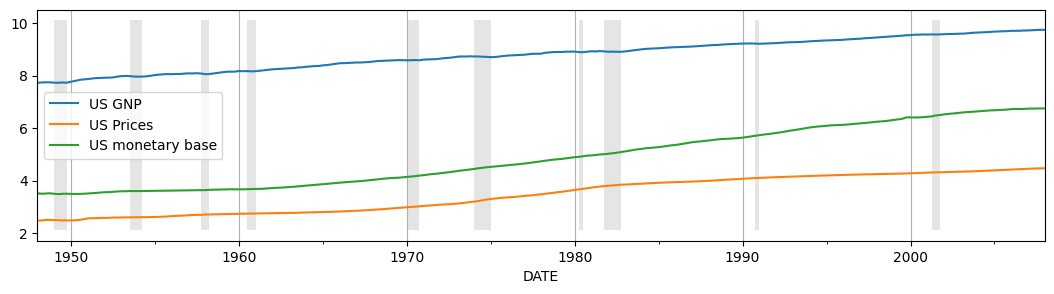
為了瞭解這三個變數在時間範圍內的變化,我們可以繪製它們的圖形
[3]:
# Plot the data
ax = dta.plot(figsize=(13,3))
ylim = ax.get_ylim()
ax.xaxis.grid()
ax.fill_between(dates, ylim[0]+1e-5, ylim[1]-1e-5, recessions, facecolor='k', alpha=0.1);
模型¶
由於資料已經過季節性調整,並且沒有明顯的解釋變數,因此考慮的通用模型為
假設不規則成分是白雜訊,循環是隨機且阻尼的。最終的建模選擇是要用於趨勢成分的規範。Harvey 和 Jaeger 考慮了兩個模型:
局部線性趨勢(「不受限」模型)
平滑趨勢(「受限」模型,因為我們強制 \(\sigma_\eta = 0\))
以下,我們為每個模型類型建構 kwargs 字典。請注意,有兩種方法可以指定模型。一種方法是直接指定成分,如上表所示。另一種方法是使用對應於各種規範的字串名稱。
[4]:
# Model specifications
# Unrestricted model, using string specification
unrestricted_model = {
'level': 'local linear trend', 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
}
# Unrestricted model, setting components directly
# This is an equivalent, but less convenient, way to specify a
# local linear trend model with a stochastic damped cycle:
# unrestricted_model = {
# 'irregular': True, 'level': True, 'stochastic_level': True, 'trend': True, 'stochastic_trend': True,
# 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
# }
# The restricted model forces a smooth trend
restricted_model = {
'level': 'smooth trend', 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
}
# Restricted model, setting components directly
# This is an equivalent, but less convenient, way to specify a
# smooth trend model with a stochastic damped cycle. Notice
# that the difference from the local linear trend model is that
# `stochastic_level=False` here.
# unrestricted_model = {
# 'irregular': True, 'level': True, 'stochastic_level': False, 'trend': True, 'stochastic_trend': True,
# 'cycle': True, 'damped_cycle': True, 'stochastic_cycle': True
# }
我們現在擬合以下模型
產出,不受限模型
價格,不受限模型
價格,受限模型
貨幣,不受限模型
貨幣,受限模型
[5]:
# Output
output_mod = sm.tsa.UnobservedComponents(dta['US GNP'], **unrestricted_model)
output_res = output_mod.fit(method='powell', disp=False)
# Prices
prices_mod = sm.tsa.UnobservedComponents(dta['US Prices'], **unrestricted_model)
prices_res = prices_mod.fit(method='powell', disp=False)
prices_restricted_mod = sm.tsa.UnobservedComponents(dta['US Prices'], **restricted_model)
prices_restricted_res = prices_restricted_mod.fit(method='powell', disp=False)
# Money
money_mod = sm.tsa.UnobservedComponents(dta['US monetary base'], **unrestricted_model)
money_res = money_mod.fit(method='powell', disp=False)
money_restricted_mod = sm.tsa.UnobservedComponents(dta['US monetary base'], **restricted_model)
money_restricted_res = money_restricted_mod.fit(method='powell', disp=False)
在擬合這些模型後,有多種方法可以顯示資訊。查看美國 GNP 模型,我們可以使用擬合物件上的 summary 方法來總結模型的擬合情況。
[6]:
print(output_res.summary())
Unobserved Components Results
=====================================================================================
Dep. Variable: US GNP No. Observations: 241
Model: local linear trend Log Likelihood 769.972
+ damped stochastic cycle AIC -1527.945
Date: Thu, 03 Oct 2024 BIC -1507.136
Time: 15:50:16 HQIC -1519.558
Sample: 01-01-1948
- 01-01-2008
Covariance Type: opg
====================================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------------
sigma2.irregular 1.399e-06 7.35e-06 0.190 0.849 -1.3e-05 1.58e-05
sigma2.level 2.775e-06 4.97e-05 0.056 0.955 -9.47e-05 0.000
sigma2.trend 3.199e-06 1.48e-06 2.162 0.031 2.99e-07 6.1e-06
sigma2.cycle 3.871e-05 2.55e-05 1.517 0.129 -1.13e-05 8.87e-05
frequency.cycle 0.4496 0.047 9.548 0.000 0.357 0.542
damping.cycle 0.8672 0.042 20.564 0.000 0.785 0.950
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 9.27
Prob(Q): 1.00 Prob(JB): 0.01
Heteroskedasticity (H): 0.26 Skew: -0.04
Prob(H) (two-sided): 0.00 Kurtosis: 3.97
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
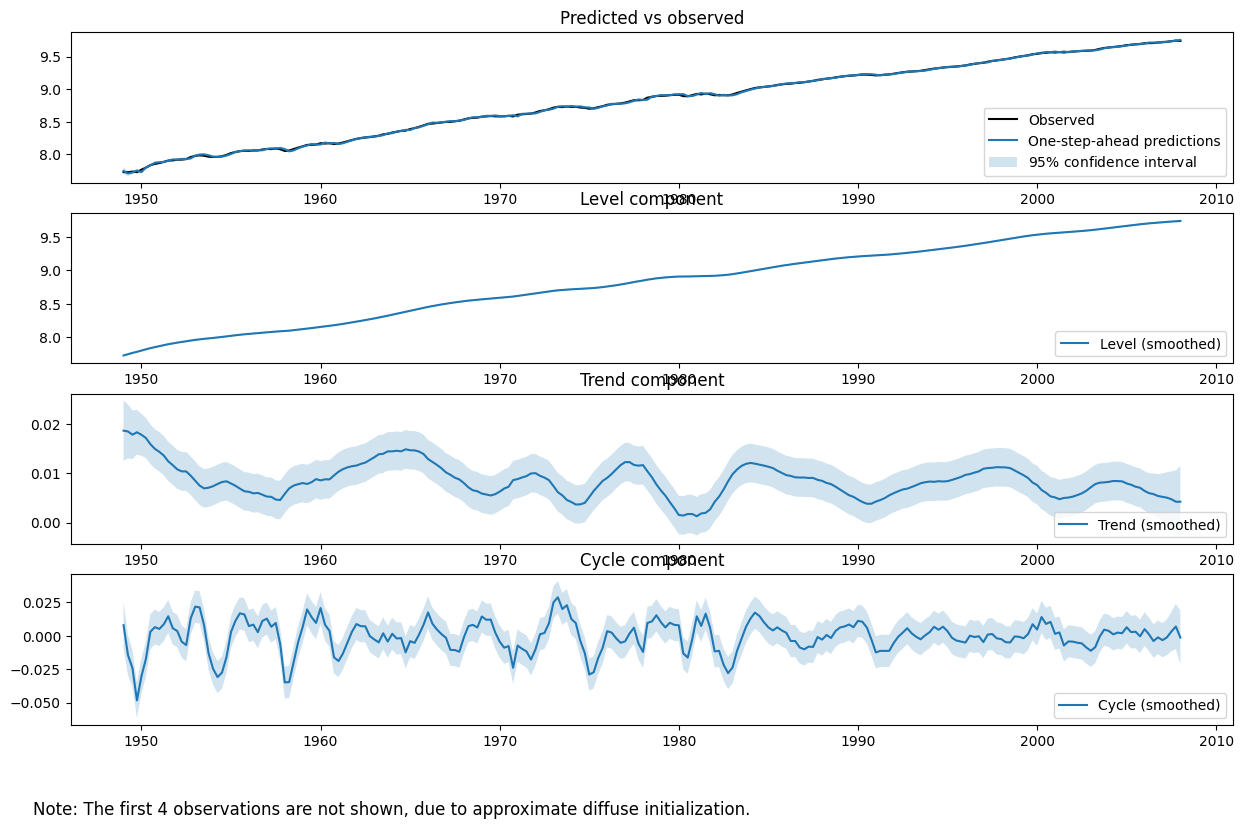
對於未觀察到的成分模型,特別是在探索符合引言中第 (2) 點的典型化事實時,繪製估計的未觀察到的成分(例如,水準、趨勢和循環)本身通常更能說明問題,以查看它們是否提供資料的有意義描述。
擬合物件的 plot_components 方法可用於顯示每個估計狀態的圖表和信賴區間,以及觀察到的數據與模型單步提前預測值的圖表,以評估擬合程度。
[7]:
fig = output_res.plot_components(legend_loc='lower right', figsize=(15, 9));
/opt/hostedtoolcache/Python/3.10.15/x64/lib/python3.10/site-packages/statsmodels/tsa/statespace/structural.py:1738: RuntimeWarning: invalid value encountered in sqrt
std_errors = np.sqrt(component_bunch['%s_cov' % which])
最後,Harvey 和 Jaeger 以另一種方式總結了模型,以突顯趨勢和週期性成分的相對重要性;下面我們複製了他們的表 I。我們發現的值與他們表中的值大致一致,但在細節上有所不同。
[8]:
# Create Table I
table_i = np.zeros((5,6))
start = dta.index[0]
end = dta.index[-1]
time_range = '%d:%d-%d:%d' % (start.year, start.quarter, end.year, end.quarter)
models = [
('US GNP', time_range, 'None'),
('US Prices', time_range, 'None'),
('US Prices', time_range, r'$\sigma_\eta^2 = 0$'),
('US monetary base', time_range, 'None'),
('US monetary base', time_range, r'$\sigma_\eta^2 = 0$'),
]
index = pd.MultiIndex.from_tuples(models, names=['Series', 'Time range', 'Restrictions'])
parameter_symbols = [
r'$\sigma_\zeta^2$', r'$\sigma_\eta^2$', r'$\sigma_\kappa^2$', r'$\rho$',
r'$2 \pi / \lambda_c$', r'$\sigma_\varepsilon^2$',
]
i = 0
for res in (output_res, prices_res, prices_restricted_res, money_res, money_restricted_res):
if res.model.stochastic_level:
(sigma_irregular, sigma_level, sigma_trend,
sigma_cycle, frequency_cycle, damping_cycle) = res.params
else:
(sigma_irregular, sigma_level,
sigma_cycle, frequency_cycle, damping_cycle) = res.params
sigma_trend = np.nan
period_cycle = 2 * np.pi / frequency_cycle
table_i[i, :] = [
sigma_level*1e7, sigma_trend*1e7,
sigma_cycle*1e7, damping_cycle, period_cycle,
sigma_irregular*1e7
]
i += 1
pd.set_option('float_format', lambda x: '%.4g' % np.round(x, 2) if not np.isnan(x) else '-')
table_i = pd.DataFrame(table_i, index=index, columns=parameter_symbols)
table_i
[8]:
| $\sigma_\zeta^2$ | $\sigma_\eta^2$ | $\sigma_\kappa^2$ | $\rho$ | $2 \pi / \lambda_c$ | $\sigma_\varepsilon^2$ | |||
|---|---|---|---|---|---|---|---|---|
| 系列 | 時間範圍 | 限制 | ||||||
| 美國國民生產總值 | 1948:1-2008:1 | 無 | 27.75 | 31.99 | 387.1 | 0.87 | 13.98 | 13.99 |
| 美國物價 | 1948:1-2008:1 | 無 | 0 | 61.88 | 20.71 | 0.43 | 6.55 | 0 |
| $\sigma_\eta^2 = 0$ | 61.92 | NaN | 20.69 | 0.43 | 6.55 | 0 | ||
| 美國貨幣基礎 | 1948:1-2008:1 | 無 | 68.75 | 18.86 | 192.7 | 0.89 | 23.19 | 0 |
| $\sigma_\eta^2 = 0$ | 18.92 | NaN | 247.1 | 0.89 | 23.8 | 0 |